download articolo+codice (la versione finale della classe è nella directory 3 nello zip)
Nota: un'altra ragionevole scelta implementativa è utilizzare array dinamici di dimensione variabile. Si ha il vantaggio di una maggiore semplicità rispetto alla gestione di una lista a puntatori, che si paga però con l'overhead dovuto al ridimensionamento, che è tanto maggiore quanto minore memoria si vuole occupare ad un tempo.
Lo stato predefinito di un oggetto stack, come stabilito dal costruttore senza argomenti, è quello di pila vuota. Il passaggio del parametro di push avviene per riferimento costante, per evitare l'overhead della copia nel caso T sia un tipo di grosse dimensioni.
Eccezioni: nel caso di memoria heap esaurita push lancia una eccezione MemoryOut. Il tentativo di estrarre (con pop) un elemento quando la pila è vuota lancia una eccezione StackEmpty. Se preferite la diagnostica con assert, uncommentate la #define ASSERT_YES e ricompilate.
// a simple class stack - feel free to use or copy this code
#ifndef stack_H
#define stack_H
// #define ASSERT_YES
#include <stdlib.h> // for NULL
#include <assert.h> // for macro assert()
template <class T>
class stack
{
public:
#ifndef ASSERT_YES
// exceptions
class MemoryOut {};
class StackEmpty {};
#endif
stack( ): sp(NULL) {}
stack(const stack& s) { stackcpy(s); }
~stack() { clear( ); }
const stack& operator=(const stack&);
void push(const T& val);
T pop( );
void clear( );
protected:
struct node
{
T val;
node* prev;
};
node* sp;
// stack pointer
void stackcpy(const stack&);
// this is inline
// note that it is NOT a member function
// (this is what static means)
inline static node* new_node() // inline here is optional
{
node* pnode=new node;
#ifndef ASSERT_YES
if (pnode==NULL)
throw MemoryOut( );
#else
assert(pnode !=
NULL);
#endif
return pnode;
}
};
template <class T>
void stack<T>::stackcpy(const stack<T>& s)
{
n=s.n;
if (s.sp != NULL)
{
node* tail= new_node();
const node* ssp=s.sp; // cursor on
the list s.sp
node* tmp;
// first copy the top
sp= tail;
sp->val = ssp->val;
// then all the other elements in
order
while ((ssp = ssp->prev) != NULL)
{
tmp=new_node();
tail->prev = tmp;
tail = tmp;
tail->val = ssp->val;
}
tail->prev = NULL;
}
else
sp=NULL;
}
template <class T>
const stack<T>& stack<T>::operator=(const stack<T>&
s)
{
clear();
stackcpy(s);
return (*this);
}
template <class T>
void stack<T>::push(const T& val)
{
node* tmp= new_node();
tmp->val=val;
tmp->prev=sp;
sp=tmp;
}
template <class T>
T stack<T>::pop( )
{
#ifndef ASSERT_YES
if (sp==NULL) throw StackEmpty(
);
#else
assert(sp != NULL);
#endif
T val= sp->val;
node* tmp= sp;
sp=sp->prev;
delete tmp;
return(val);
}
template <class T>
void stack<T>::clear( )
{
for (node* q = sp; q != NULL; q = sp)
// or sp != NULL
{
sp = sp->prev;
delete q;
}
}
#endif
Distruttore, costruttore di copia, operatore di assegnamento vanno ridefiniti opportunamente per evitare perdite di memoria dinamica e indesiderata condivisione di memoria dinamica tra gli oggetti copiati. Poichè costruttore di copia ed operatore = condividono l'azione di copia della lista linkata, è stata creata una funzione membro privata apposita per questa operazione (stackcpy). Notare che la "destinazione" della copia di stackcpy è l'oggetto proprio; il parametro è la "sorgente" ed è del tipo riferimento a costante. In questo caso comunque, essendo le dimensioni di un oggetto stack ridotte è altrettanto appropriato anche il passaggio per valore.
Inoltre distruttore ed operatore di assegnamento condividono il codice che consiste nel deallocare tutta la parte dinamica. Per evitare ripetizioni ho inserito questo codice comune in una funzione membro apposita, detta clear. Ho deciso di rendere questa funzione pubblica anzichè protetta, in quanto è utile avere un metodo per svuotare completamente lo stack.
Il compilatore della GNU permette di invocare direttamente il distruttore per distruggere un oggetto, anche un oggetto di invocazione di un metodo. Questo risulta in alcuni casi utile, perchè si può distruggere parzialmente un oggetto voluminoso esplicitamente, prima che venga distrutto implicitamente quando va fuori scope, in modo da liberare memoria prima. E se si fa in modo che l'oggetto dopo la distruzione parziale (ossia della sola estensione dinamica) assume uno stato iniziale corretto, non ci sono pericoli a riutilizzarlo. Tenete presente comunque che all'uscita dall'ambito di visibilità il distruttore viene sempre chiamato, anche dopo che lo avete chiamato esplicitamente, perciò occorre assicurarsi che una successiva sua chiamata non produca problemi. In questo caso non produrrebbe problemi, perchè quando sp è NULL, il codice in clear( ) non fa nulla.
Comunque un compilatore intelligente potrebbe inserire la chiamata del distruttore subito dopo l'ultima istruzione nello scope che utilizza quell'oggetto, facendo per noi questa piccola ottimizzazione di spazio.
Stroustrup ha deciso che il distruttore, che viene chiamato automaticamente, non si può chiamare esplicitamente in nessun caso ed io sono daccordo, perchè se il compilatore è intelligente non se ne ha mai bisogno (credo). Anche se un compilatore lo permette, non dovreste chiamarlo per ragioni di portabilità ovviamente, oltreche di bellezza formale (è molto meglio e più semplice che venga chiamato in automatico).
Come programma di test eccone uno che legge da input una serie di caratteri e li stampa in ordine inverso. Naturalmente questo è un modo per niente efficiente di risolvere questo semplice problema e serve solo per dimostrazione e per testare la classe:
#include <iostream.h>
#include "stack.h"
int main()
{
stack<char> s;
int c;
while ((c=cin.get())!=EOF)
s.push(c);
try
{
while (1)
cout <<
s.pop( );
}
catch (stack<char>::StackEmpty) { }
return(0);
}
Potete trovare il codice della prima versione e questo programma di
test nella directory 1 dentro lo zip.
#include <iostream.h>
#include "stack.h"
int main()
{
stack<char> s;
int c;
while ((c=cin.get())!=EOF)
try { s.push(c); }
catch (stack<char>::MemoryOut)
{ exit(-1); }
while (!s.empty( ))
cout << s.pop( );
exit(0);
}
Un nuovo metodo full restituisce true se la memoria dinamica è esaurita. Questo metodo funziona allocando new per vedere se c'è ulteriore spazio per allocare un nodo. Se lo spazio non c'è ritorna true, altrimenti disalloca il nodo appena allocato al solo scopo di testare lo stato dello heap e ritorna false.
Il metodo top restituisce l'elemento in cima allo stack senza prelevarlo. Per ragioni di efficienza e per permettere la modifica dell'elemento in cima liberamente, esso restituisce un riferimento a T non costante. Questo significa che potete scrivere cose ad esempio del tipo:
stack<int> s;
s.push(5);
s.push(3);
// lo stack è:
// 3
// 5
++s.top();
// ora lo stack è
// 4
// 5
Inoltre adesso è possibile disattivare il trapping degli errori, #definendo NOERROR_TRAP. Se si è sicuri che non possono verificarsi errori, la cosa ha senso per minimizzare la lunghezza del codice. Ovviamente nella fase di debugging del programma utente conviene non farlo.
Inoltre il codice con inclusione condizionale di pop e top che gestisce in qualche modo l'errore che si ha chiamando queste funzioni quando la pila è vuota, è lo stesso, quindi l'ho riunito in una funzione inline, in modo da avere tutto il codice di gestione delle eccezioni in un solo punto, nella definizione della classe.
Nota: attenzione agli effetti collaterali. Sul mio compilatore (DJGPP), i due frammenti di codice:
cout << s.pop( ) << endl << s.pop( ) << endl;
e
cout << s.pop( ) << endl;
cout << s.pop() << endl;
danno effetti differenti. Se lo stack era (top)3 5, la prima stampa 5 3 ! Questo perchè non è garantito l'ordine con cui le due chiamate pop( ) vengono valutate. Lo standard stabilisce che << è un operatore associativo da sinistra verso destra ma non stabilisce niente riguardo l'ordine di valutazione degli argomenti di una funzione o degli argomenti di una catena di operatori (ricordo che la chiamata di un operatore definito dal programmatore equivale alla chiamata della corrispondente funzione operator, quindi è sia concettualmente che praticamente la chiamata di una funzione, a meno che non sia inline). All'atto pratico la maggior parte delle implementazioni passa gli argomenti da destra verso sinistra, perchè questo è un modo efficiente su molte macchine per gestire le liste di argomenti variabili e per ottimizzare li valuta allo stesso modo. Questo spiega perchè la prima espressione:
cout << s.pop( ) << endl << s.pop( ) << endl;
ha dato come risultato 5 3. Per semplificare, togliamo gli endl:
cout << s.pop( ) << s.pop( );
Allora essa equivale a:
( cout.operator<<(s.pop( )) ).operator<<(s.pop( ))
e l'ordine di valutazione degli argomenti non è definito. In DJGPP ad es. succede che vengono valutati da sinistra verso destra. L'operatore chiamato per prima sarà ovviamente sempre quello più a sinistra, anche se non avessimo scritto le parentesi, poichè l'operatore di selezione di membro di classe (.) è associativo da sinistra a destra.
Anche se si conosce l'ordine di valutazione di un particolare compilatore, non è comunque buona norma farvi affidamento, perchè ovviamente ciò renderebbe i programmi non portabili.
Lo standard lascia appositamente libertà riguardo all'ordine
di valutazione affinchè le implementazioni possano fare la scelta
di volta in volta più conveniente.
Dividere interfaccia e implementazione
In questa terza versione, la modifica sostanziale è che l'implementazione e la dichiarazione sono stati separati in due file .H e .CPP. E' stato comunque dovuto prendere un accorgimento: il problema è che occorre far sì che vengano sempre generate tutte le istanze del modello di classe che si utilizzano. Se qualche istanza non viene generata dal compilatore, il linker si lamenterà con errori tipo "undefined references to <nome metodo che doveva essere istanziato>" (ricordate infatti che il linker ovviamente non genera codice! solo il compilatore è in grado di generare codice).
La soluzione più semplice per questo problema consiste nel mettere tutto il codice in un file .H. Tuttavia presenta un inconveniente: ci sono problemi di doppie definizioni quando si linkano due o più moduli che entrambi definiscano la stessa istanza di un modello (ad es. due moduli che entrambi autonomamente definiscono uno stack di interi). La pratica di mettere tutto in un file .H va quindi evitata, avevo fatto così solo per semplicità nella fase di sviluppo.
Nota: con il linker intelligente di GCC non si verificano problemi di doppie definizioni; al linker vengono passate sufficienti informazioni nei file oggetto in modo che esso capisce che i moduli hanno istanziato la stessa classe template e scarta quindi una o più istanze identiche. Lo stesso capita con Borland C++ e probabilmente con qualsiasi altro compilatore che si rispetti. Tuttavia mettere tutto in un file .H può essere svantaggioso in grossi progetti e nel caso si abbiano grandi e numerose classi template per il fatto che può allungare i tempi di compilazione, come spiegherò a breve.
Una soluzione più corretta consiste nel separare interfaccia e implementazione (per quanto possibile, infatti i modelli dei metodi inline dovranno essere definiti per forza nel file header) e inserire poi nel modulo di implementazione delle definizioni con la sola funzione di istanziare tutte le istanze della classe template necessarie al programma. In questo modo i moduli che utilizzano le istanze, di fatto non istanziano le funzioni membro non inline, perchè non ne hanno la definizione ma solo la dichiarazione e fanno riferimento alle istanziazioni presenti in questo modulo e non ci possono essere problemi di doppie definizioni, essendo tutte le definizioni in un unico modulo.
Ecco le dichiarazioni che istanziano il modello da aggiungere nel file di implementazione stack.cc:
// stack.cc
#include "stack.h"
template class stack<int>; // qui
class è opzionale
template class stack<char>;
...
Questo procedimento non solo evita errori in fase di linking (possibili con un linker poco intelligente), ma, anche quando questi non si verificherebbero, perchè ogni modulo istanzia classi diverse (con diversi tipi), riduce i tempi di make di un progetto, in quanto i file utente ora sono composti da meno codice da ricompilare e le istanze verranno quindi generate una sola volta quando si compila il file di implementazione se non si modifica mai il modello e ovviamente non si aggiungono nuove istanze.
Per fare il rebuild del programma 3/test.cc ad es. occorre:
// stack_i.cc
#include "stack.h"
#include "stack.cc"
template class stack<int>;
// stack_c.cc
#include "stack.h"
#include "stack.cc"
template class stack<char>;
I moduli utente invece includeranno solo stack.h e questo assicura che essi non generino istante complete; si genera una sola istanza per ogni tipo compilando il rispettivo file stack_tipo.cc. In questo modo ogni volta che si vuole istanziare la classe template con un nuovo tipo si crea un nuovo file "istanziatore" stack_nuovotipo.cc e gli altri file "istanziatori" non dovranno essere ricompilati. Ovviamente tutti i file istanziatori sono dipendenti da stack.h e stack.cc e dovranno essere ricompilati se quest'ultimi cambiano. Il file stack.cc stranamente non ha più bisogno di essere compilato, anche se è innocuo compilarlo e linkarlo nel progetto finale.
Ho anche aggiunto un altra funzione dtop (che sta per double top) e che ha l'effetto di duplicare l'elemento in cima allo stack e restituisce, come top, un riferimento al valore duplicato. Questo riferimento come nel caso di top è un riferimento a non-costante. Il valore restituito è per definizione la copia che è nella nuova cima dello stack:
template <class T>
T& stack<T>::dtop( )
{
// notare che top gestisce l'eccezione pila vuota
// quindi non dobbiamo gestirla qui
push(top( ));
return sp->val;
}
Debugging e manutenzione
Qualunque programmatore sa quanto lavoro si nasconde dietro questi due compiti apparentemente secondari. Le cose sono sempre difficili quando si deve mettere mano a qualcosa che si è scritto anche solo qualche mese fa. Se poi dovete mettere mano a del codice di un programmatore meno bravo di voi è una noia: meglio riscrivere tutto daccapo. Più si usa una classe senza riscontrare problemi e più ci si può fidare della sua correttezza. Questo dovrebbe aiutare a localizzare gli errori, ma sfortunatamente i casi d'uso di una classe (come pure di un intero programma) sono talmente tanti che non è possibile dimostrare la correttezza, ovvero esserne sicuri matematicamente. I "nasty bug", cioè i bachi difficili da scovare, sono delle grosse grane che fanno perdere un sacco di tempo e energie ai programmatori di tutto il mondo. Ma non è umanamente possibile scrivere un grosso programma del tutto privo di bachi di primo acchitto. I bug sono una realtà con la quale bisogna imparare a convivere. Ogni volta che il computer dell'utente si blocca costringendolo a riavviare, la colpa è certamente del programmatore (compresi di quelli che programmano certi sistemi operativi, soprattutto quelli che iniziano con la W).
Ecco un "nasty bug" annidato nel nostro codice della classe stack: l'operator= non si comporta bene quando scrivo ad es. s=s. Per il costruttore di copia non ci sono problemi, in quanto non posso scrivere ad es. stack<int> s(s);
Ad es. compilando ed eseguendo questo programma di prova, e attivando ASSERT_YES in stack.h
#include <iostream.h>
#include "stack.h"
int main()
{
stack<int> s;
s.push(5);
s=s;
cout << s.pop() << endl;
return(0);
}
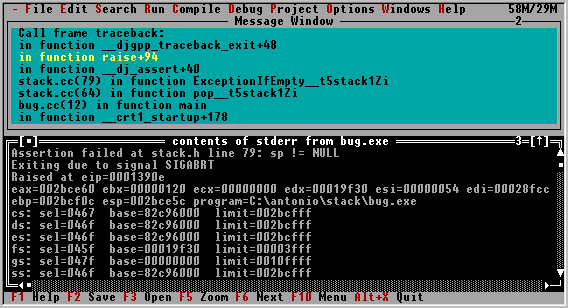
con DJGPP si ottiene un errore run-time. Il segnale SIGABRT viene mandato al programma da assert. Il programma risponde terminando se stesso. Notate che sappiamo la linea di codice dove si verifica l'errore: era la linea 79 di stack.h nel mio caso, quindi vuol dire che si è verifica una eccezione del tipo ExceptionIfEmpty. Sappiamo che solo pop e top generano questa. Siccome abbiamo chiamato pop( ), allora è questo il problema, come confermato quando si traccia il programma.
Tuttavia questo non significa che l'errore logico, il vero è
proprio errore di programmazione sia in pop( ). Riguardando questa procedura
potete vedere che è corretta. Dov'è l'errore, allora? Come
potete vedere gli effetti disastrosi di un errore possono manifestarsi
anche dopo, in questo caso piuttosto vicino, poichè l'errore è
nella istruzione precedente s=s, ma in altri casi più complessi
anche piuttosto lontano. Un nasty bug è un errore che il programmatore
non riesce a spiegarsi e molto spesso deve rompersi la testa per scovarlo.
Tracciando il programma passo passo si scopre appunto l'errore in s=s;,
ossia in operator= della classe stack.
template <class T>
const stack<T>& stack<T>::operator=(const stack&
s)
{
clear();
stackcpy(s);
return (*this);
}
se s è lo stesso dell'oggetto proprio, clear( ) prima libera
la memoria allocata rendendo n=0 e sp=NULL e poi stackcpy copia su stesso
un oggetto stack vuoto, il che è innocuo. In pratica lo stack viene
svuotato, ed ecco quindi perchè la pop( ) lanciava l'eccezione di
stack vuoto.
La correzione consiste nel non fare niente se s è pari all'oggetto
proprio:
template <class T>
const stack<T>& stack<T>::operator=(const stack<T>&
s)
{
if (this == &s)
{
clear();
stackcpy(s);
}
return (*this);
}
A questo punto il programma è corretto, come si può verificare
ricompilando bug.cc
Qualcuno potrebbe obiettare che s=s è una istruzione sciocca,
e che nessuno scriverebbe mai una cosa del genere. E' vero, nessun utente
della classe scriverebbe mai una cosa del genere, ma potrebbe capitare
un s=t e capitare che t è un riferimento ad s, oppure potrebbe scrivere
*s=*t dove s e t sono due puntatori al tipo stack che hanno lo stesso valore
(puntano allo stesso oggetto).
Un'ultima funzione che implementiamo per completare la nostra classe stack è quella che dice se due stack sono uguali o sono diversi. Per definizione due stack sono uguali se sono entrambi vuoti o hanno gli stessi elementi (in ordine). L'algoritmo più conveniente per controllare se due stack sono uguali o meno consiste nei seguenti passi:
template <class T>
bool stack<T>::operator == (const stack<T>& s)
{
if (this == &s)
return true;
if (n != s.n)
return false;
for (node *c1=sp, *c2=s.sp; c1 != NULL; c1=c1->prev,
c2=c2->prev)
if (c1->val!=c2->val)
return false;
return true;
}
L'operator != possiamo scriverlo allora semplicemente negando ==. Lo facciamo inline per ragioni di efficienza:
bool operator != (const stack& s) { return !((*this)==s); }
Penso di aver esaurito tutte le funzionalità fondamentali su
una struttura puramente a stack. Se ne ho mancato qualcuna che vi serve,
fatemelo sapere e la implementerò. Viceversa se implementate voi
qualcos'altro perchè non condividere il codice con qualcun altro?
download articolo+codice (la
versione finale della classe è nella directory 3 nello zip)