 Figura 3-1. Una pagina del sito inglese del
Politecnico di Milano all'URL: http://www.polimi.it/english/depart.htm (non più attivo)
Figura 3-1. Una pagina del sito inglese del
Politecnico di Milano all'URL: http://www.polimi.it/english/depart.htm (non più attivo)Questo testo è il risultato di uno studio che ho effettuato nel lontano 2001 quando lavoravo all'Ufficio Web del Politecnico di Milano (SIWA, Sistema Informativo Web Ateneo). Da allora XML non ha ancora preso piede sul web, si continua ad usare HTML o al più XHTML. Nonostante l'età il testo può essere ancora utile come introduzione all'uso di XML sul web.
---->cerca "paragrafo" e crea tutti i link
Questo documento presenta alcuni esempi di utilizzo di XML e di alcune tecnologie correlate (CSS, XLink, XPath, XSLT e DTD) allo scopo di metterne in evidenza vantaggi e svantaggi. Inoltre vengono brevemente descritti alcuni tool e programmi per lavorare con XML, sia lato client che server. Non sono stati descritti tool basati su Java. Anche se ce ne sono degli ottimi, per ragioni di efficienza ho preferito consigliare solo tool scritti tramite linguaggi molto veloci tipo C/C++ e possibilmente portabili tra le piattaforme da noi più utilizzate (Unix/Win).
Il testo non è inteso come un vero e proprio tutorial su XML, anche se qua e là verranno dati alcuni dettagli tecnici. Gli esempi allegati possono essere provati e compresi nelle loro linee generali anche senza conoscere approfonditamente XML. Il testo presente sarà soggetto a modifiche e correzioni eventuali. I cambiamenti saranno descritti brevemente nel paragrafo seguente.
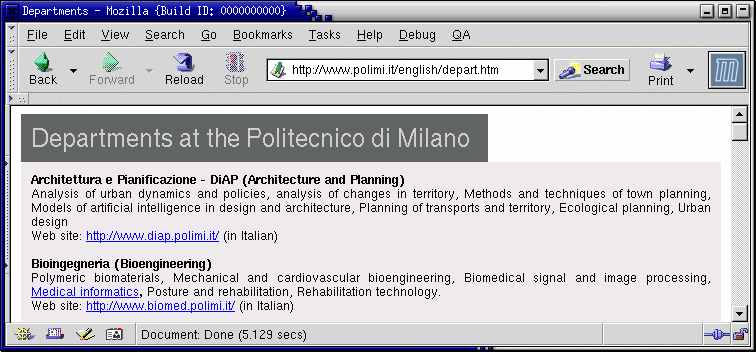
Consideriamo per esempio una pagina molto semplice del sito inglese del Politecnico di Milano:
Figura 3-1. Una pagina del sito inglese del
Politecnico di Milano all'URL: http://www.polimi.it/english/depart.htm (non più attivo)
Nonostante la pagina venga visualizzata correttamente, il sorgente di questa pagina non è ben formato e non è facilmente comprensibile per chi non conosca alcuni dettagli di HTML e inoltre non è ben indentato e ci sono alcuni tag spuri. Tutto questo rende difficile anche solo modificare o estendere il contenuto informativo della pagina, anche indipendentemente dal fatto che l'utente conosca più o meno bene HTML. Infatti tutti i tag usati per la formattazione rendono difficile l'individuazione del testo vero e proprio che vi è annidato e inoltre rendono molto prolisso il documento. Anche chi è esperto di HTML se ad es. deve inserire delle sezioni di scripting da elaborarsi lato server, può trovare non agevole editare questo documento e commettere qualche errore con l'annidamento dei tag.
Questa pagina è stata probabilmente generata con un programma WYSIWYG per l'elaborazione di HTML non particolarmente difficile da usare, ma non dotato di parser per la verifica che l'HTML generato sia ben formato e nemmeno di un buon indentatore automatico di codice.
In realtà secondo HTML non è necessario chiudere il tag
<META>, quindi non si tratta di un errore particolarmente
grave. E' tuttavia desiderabile che anche i documenti HTML siano ben formati,
siano cioè dei documenti XML ben formati o che almeno seguano le specifiche
di XHTML.
L'utility HTML Tidy, consigliata dal W3C, automatizza in gran parte la correzione dei documenti HTML mal formati. Ho già installato questa utility nel nostro server web principale (ace.rett.polimi.it). Potete ottenere la documentazione di HTML Tidy richiamando la relativa manpage al prompt della shell:
% man 1 tidy
oppure tramite il Web all'URL (riservato): http://ace.rett.polimi.it/docs/tidy4aug00/ oppure all'URL pubblico: http://www.w3.org/People/Raggett/tidy/
Riscriviamo questo documento in XML. Inventiamo dei tag e annidiamoli correttamente. Ho scelto nomi in inglese per i tag perchè si tratta di una pagina del sito inglese, ma nulla vieta di usare nomi in italiano.
<?xml version="1.0" standalone="yes"?> <departments> <title>Departments at the Politecnico di Milano</title> <department> <name> <italian>Architettura e Pianificazione - DiAP</italian> (<english>Architecture and Planning</english>) </name> <description> Analysis of urban dynamics and policies, analysis of changes in territory, Methods and techniques of town planning, Models of artificial intelligence in design and architecture, Planning of transports and territory, Ecological planning, Urban design. </description> Web site: <website><url>http://www.diap.polimi.it/</url> (<lang>in Italian</lang>)</website> </department> <department> ... </department> </departments>
Deve sempre esserci un tag che racchiuda tutti gli altri tag del
documento, così come il tag <HTML> di HTML. Nell'esempio
ho scelto il nome departments come tag radice. Poichè nel
Paragrafo 5 formatteremo questo documento tramite un foglio di stile CSS, non
ho inventato attributi negli elementi perchè CSS non li supporta e non
saremmo quindi in grado di visualizzare il valore dell'attributo. Perciò ho
usato solo elementi annidati.
Nota: con l'uscita di CSS2 è possibile visualizzare il valore di attributi XML tramite CSS. Si può definire una regola per inserire il valore dell'attributo prima (usando il pseudo-elemento :before) o dopo (:after) il tag che lo contiene. Si usa la dichiarazione content che permette appunto di cambiare il contenuto di un elemento. Tuttavia non si può inserire codice HTML, un eventuale tag come ad es. <a> verrebbe mostrato letteralmente. Inoltre, dal momento che rappresenta un modo per aggiungere contenuto alla pagina tramite CSS (che dovrebbe invece limitarsi solo a definire la presentazione), meglio non usarla. Per chiarire ecco un esempio:
website.xml:
<?xml version="1.0" standalone="yes"?>
<?xml-stylesheet type="text/css" href="style.css"?>
<website url="http://www.diap.polimi.it/" lang="ita" />
style.css:
website:before {
content: 'Web site: ' attr(url);
}
In seguito verrà mostrato come aggiungere i link tramite XLink.
Ad es. ho annidato l'elemento di nome url nell'elemento
website anziché creare un attributo url
nell'elemento website. Nel Paragrafo 7 useremo XSLT per
automatizzare la trasformazione di questo documento XML in HTML e lo
riscriveremo usando gli attributi dove ci parrà opportuno.
In generale non c'è una regola fissa che dica quando sia meglio memorizzare un certo pezzo di informazione come elemento o attributo di un elemento. C'è solo il fatto che gli elementi possono contenere altri elementi innestati, ma gli attributi no. Volendo fare un paragone con la linguistica gli attributi hanno una funzione aggettivale (cioè sono analoghi agli aggettivi che qualificano un nome), mentre gli elementi hanno una funzione nominale.
Una fase molto importante del processo di markup, che precede la scrittura del codice XML consiste nell'analisi del documento esistente allo scopo di individuarne i componenti della struttura. A tale scopo possono aiutare a generare il codice XML le seguenti rappresentazioni della struttura di un documento, che si mappano direttamente sul codice XML:
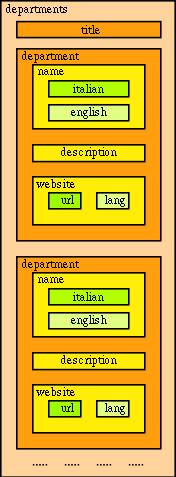 Diagramma a blocchi di depart.xml |
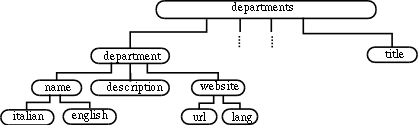 Diagramma ad albero di depart.xml, per semplicità è stato disegnato un solo figlio di departments (tanto sono tutti uguali)
|
Un buon programma sotto licenza GPL per generare grafici di questo tipo per i sistemi di tipo Unix o Windows è Dia (http://www.lysator.liu.se/~alla/dia/), simile al programma commerciale Microsoft Visio (che però naturalmente funziona solo per Windows...). Tra l'altro Dia usa internamente XML e il dialetto SVG per rappresentare le sue librerie di simboli ed anche l'intero diagramma che disegnate (che comunque può essere esportato facilmente anche in tanti altri formati).
XML (eXtensible Markup Language) è molto più semplice da imparare di HTML. XML offre semplicemente un metodo per rappresentare in un file di testo informazioni strutturate. XML è un formato di interscambio dei dati e non contiene nessun tag per la formattazione. Così visualizzando un documento XML che non abbia collegato alcun foglio di style (in gergo un documento "standalone") su molti browser si vedrà il documento in forma sorgente o solo leggermente indentato e/o con qualche syntax highlighting. E non è poi tanto male che si veda il sorgente XML! XML è un formato pensato per essere leggibile sia dalle macchine, indipendentemente dal sistema operativo o la piattaforma, sia dagli uomini.
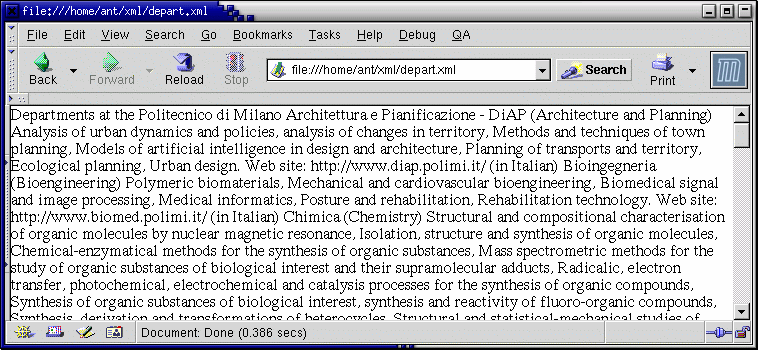
Mozilla visualizza solo il contenuto dei tag di
un documento XML standalone, ma scegliendo View/Page Source si potrà vedere
il sorgente
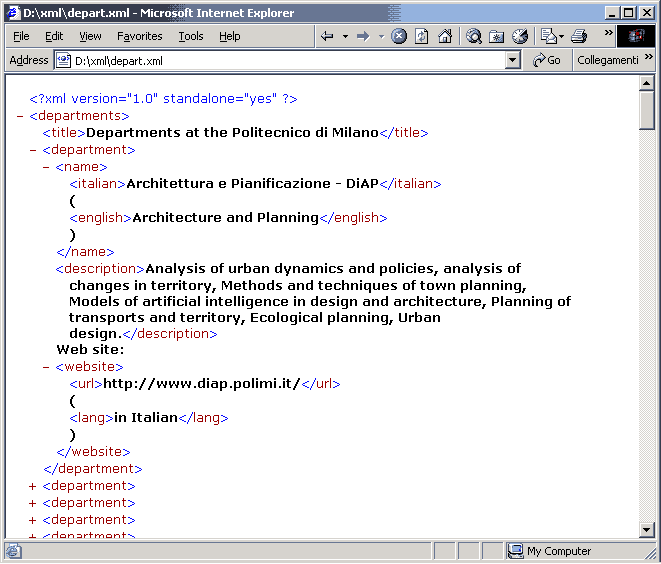
Microsoft Internet Explorer applica una trasformazione XSLT ad un
documento XML standalone allo scopo di visualizzare il sorgente con la syntax
highlighting e riformattarlo e fornire controlli HTML dinamici per
espandere/comprimere i vari rami dell'albero dei tag
Proviamo ad omettere il primo tag di chiusura
</italian> in depart.xml:
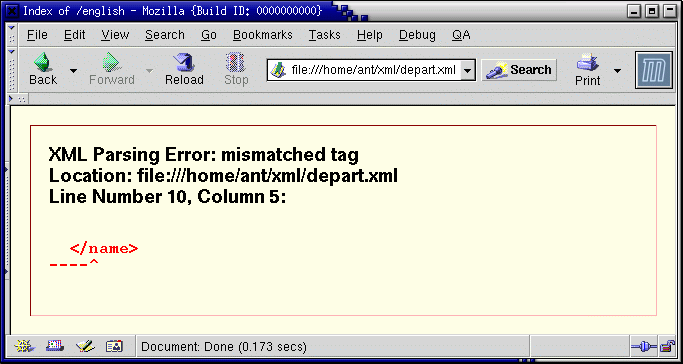
Mozilla descrive un errore in un documento XML non ben
formato
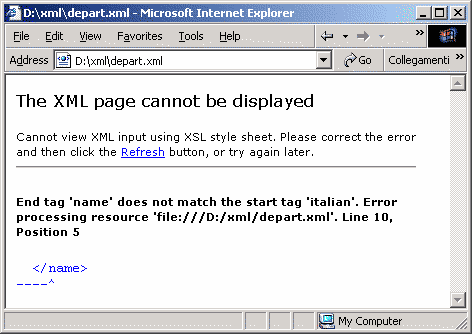
Lo stesso errore descritto stavolta dal parser di Internet
Explorer
A differenza di quello che succede con HTML quindi i browser controllano che i documenti XML siano conformi alla sintassi stabilita dal W3C che potete trovare descritta dettagliatamente qui. Le regole più importanti che un documento XML ben formato deve rispettare sono:
<br /> invece
di <br></br>.Le applicazioni di XML vanno oltre il Web: videogames, word processor, spreadsheet, applicazioni di calcolo matematico ecc.. possono tutti scegliere di usare dialetti di XML per memorizzare i propri dati invece di formati binari, garantendo così un alto livello di portabilità, semplicità, intercambiabilità, estensibilità e leggibilità. L'unico svantaggio in tal caso è che XML è più prolisso e quindi ha un maggior overhead rispetto a un formato binario. Se i file sono di piccole dimensioni, vista anche l'evoluzione continua dell'hardware, si tratta di un fattore sempre più trascurabile. Se invece bisogna rappresentare una grossa mole di dati allora conviene ricorrere ad un database nativo XML, come ad esempio l'ottimo Berkeley DB XML, che è in grado di creare degli indici per ottimizzare le ricerche e di comprimere i documenti per risparmiare spazio.
I sorgenti di questo paragrafo sono disponibili in:
Il fatto che un documento XML sia ben formato spesso non è sufficiente per assicurarne la correttezza per una particolare applicazione, similmente a come nel linguaggio naturale l'aderenza alle regole della sintassi non è sufficiente ad assicurare la correttezza di una frase. Una frase in lingua italiana per essere corretta deve anche avere senso compiuto: non basta che tutte le categorie sintattiche siano scritte correttamente, conta anche il loro ordine e solo alcune combinazioni sono valide. La stessa cosa vale anche per i tag di XML.
Il linguaggio DTD permette di definire degli schemi per la validazione semantica di un documento XML. Un documento XML che soddisfa le regole stabilite dal rispettivo programma DTD viene detto "valido". Non tutti i parser sono in grado di interpretare il linguaggio DTD. I parser che verificano la validità sono detti "validanti", mentre alcuni parser più semplici che verificano solo che il documento XML sia ben formato sono detti "non validanti". Ribadisco che il fatto che un documento sia ben formato è condizione necessaria ma non sufficiente per la validità (così come una frase in linguaggio naturale che sia sintatticamente corretta non è detto che abbia senso compiuto). Viceversa un documento valido è sicuramente anche ben formato (una frase che abbia senso compiuto deve essere per forza anche sintatticamente corretta). Difatti ogni parser validante è in realtà anche un parser non validante, ma non viceversa.
Il parser RXP utilizzato con l'HTML nel paragrafo precedente è validante. I parser che sono incorporati nei browser più diffusi (Internet Explorer, Netscape/Mozilla) non sono validanti. Internet Explorer a partire dalla versione 5 contiene tuttavia un parser validante, detto MSXML. Si tratta di un oggetto COM che fa parte della distribuzione di IE5 o superiori. Anche se non viene usato direttamente dal browser, può essere comunque utilizzato attraverso il browser stesso tramite JavaScript o VBScript. La Microsoft distribuisce alcuni script preconfezionati per utilizzare MSXML come parser, sia validante che non validante, in doppia versione JavaScript e VBScript, noti sotto il nome di XML Validator. Difatti IE usa lo stesso oggetto COM come parser non validante ogni volta che caricate un documento XML, per verificare che sia ben formato (come è stato illustrato nel paragrafo precedente).
Il programma seguente è una seconda versione del documento XML ben formato depart.xml visto nel paragrafo precedente. In depart.xml è stato ora inserito un programma DTD interno e l'intero documento risulta ora valido, oltre che naturalmente ben formato:
<?xml version="1.0" standalone="yes"?>
<!DOCTYPE departments [
<!ELEMENT departments ( title, department* )>
<!ELEMENT title ( #PCDATA )>
<!ELEMENT department ( #PCDATA | name | description | website )*>
<!ELEMENT name ( #PCDATA | italian | english )*>
<!ELEMENT italian ( #PCDATA )>
<!ELEMENT english ( #PCDATA )>
<!ELEMENT description ( #PCDATA )>
<!ELEMENT website ( #PCDATA | url | lang )*>
<!ELEMENT url ( #PCDATA )>
<!ELEMENT lang ( #PCDATA )>
]>
<departments>
<title>Departments at the Politecnico di Milano</title>
<department>
<name>
<italian>Architettura e Pianificazione - DiAP</italian>
(<english>Architecture and Planning</english>)
</name>
<description>
Analysis of urban dynamics and policies, analysis of changes in territory,
Methods and techniques of town planning, Models of artificial intelligence
in design and architecture, Planning of transports and territory,
Ecological planning, Urban design.
</description>
Web site: <website><url>http://www.diap.polimi.it/</url>
(<lang>in Italian</lang>)</website>
</department>
... ... ...
... ... ...
</department>
Le prime righe di depart.xml e l'intera DTD interna che lo valida
Nota: questa DTD non è molto restrittiva. Nel paragrafo 8, quando riscriveremo depart.xml in modo da separare completamente i dati dalla loro presentazione che sarà fatta tramite XSLT, riscriveremo anche la DTD in modo più restrittivo.
Verifichiamo con il parser RXP (o se preferite usate MSXML) che questo documento è valido:
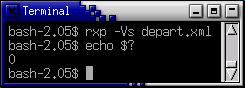
L'efficiente parser RXP verifica che depart.xml è valido secondo la DTD
contenuta internamente (valore di ritorno del test di validità: 0)
Introduciamo un errore in depart.xml tale che esso rimanga ben formato ma
non sia più valido. Per esempio italianizziamo il primo tag di apertura
<name> in <nome> e anche il primo tag
di chiusura </name> in </nome>. Ecco
l'effetto con RXP e con MSXML usati come parser non validandi e validanti:
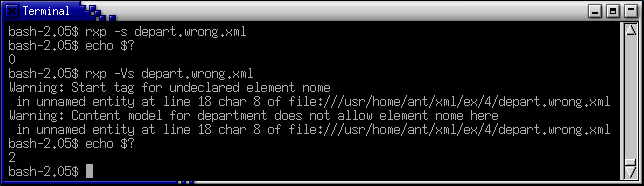
Il documento depart.wrong.xml è ben formato (codice 0), ma non valido
(codice 2) poiché l'elemento nome non è ammesso dalla DTD
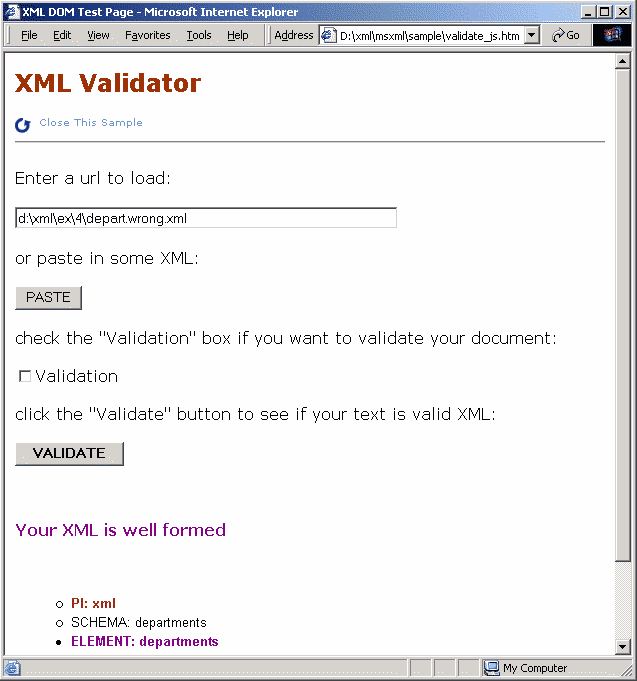
Anche MSXML (richiamato come parser non validante anche quando si visiona un
file XML con IE) riconosce che depart.wrong.xml è un documento ben formato
...
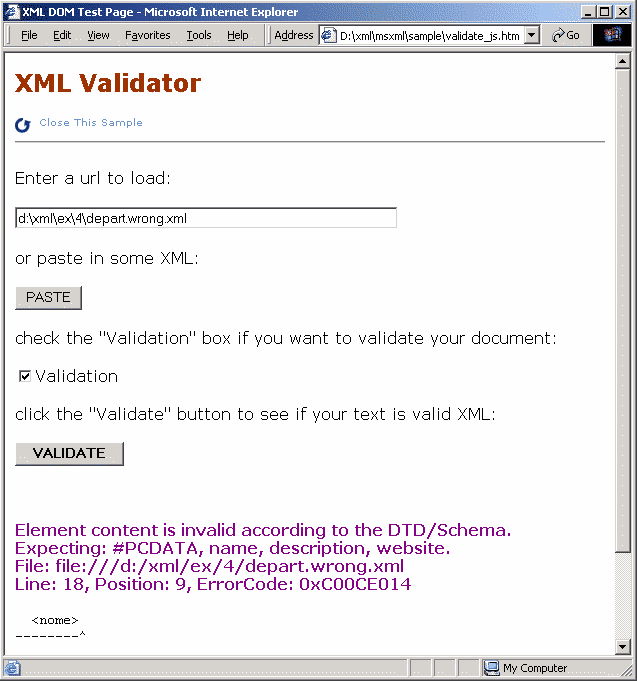
... ma non un documento valido secondo la DTD assegnata
La creazione delle DTD può essere in parte automatizzata. Esistono programmi che processando un file XML privo di DTD e supponendolo valido, tentano di generare con la maggior completezza e precisione possibile la DTD relativa. E' chiaro che le DTD così generate potrebbero non essere perfette e vanno comunque riguardate manualmente, tuttavia questi programmi costituiscono già un buon punto di partenza per accelerare i tempi di sviluppo delle DTD.
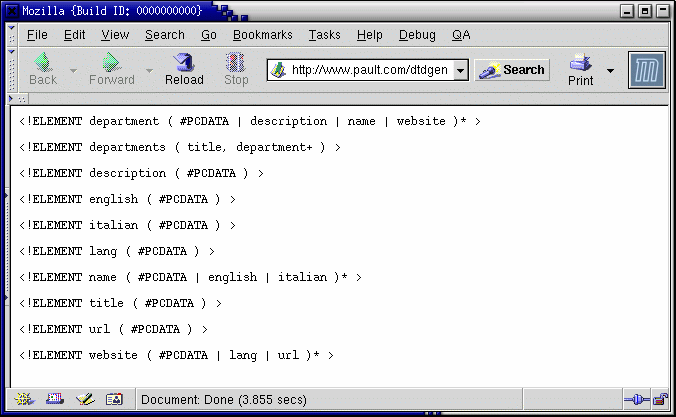
La DTD per depart.xml generata automaticamente tramite ilfrontend web di DTDGenerator
Si noti che la DTD generata tramite DTDGenerator è molto simile a quella che avevo scritto a mano, a parte l'ordine delle dichiarazioni degli elementi (che non ha alcuna importanza) e la scelta differente di alcuni indicatori di occorrenza (* e + sono indicatori di occorrenza, il primo indica una occorrenza ripetibile 0, 1 o più volte, il secondo una occorrenza ripetibile 1 o più volte).
La validazione e la possibilità di separare lo stile dai contenuti offerte dall'XML porta notevoli vantaggi, soprattutto nei siti molto grandi in cui si ha la necessità di raccogliere e pubblicare informazioni da diverse fonti (la nostra esperienza in proposito sarà descritta nel paragrafo 7).
Le specifiche di validazione semantica espresse tramite il DTD possono
essere descritte nello stesso documento XML, oppure in un file esterno
collegato al documento XML. In quest'ultimo caso più istanze XML possono
condividere la stessa DTD e le DTD possono essere definite una volta per
tutte e/o raccolte in una sola directory del sito web (es.
/dtd). Per esempio ecco come si presenta depart.xml con una DTD
esterna anziché interna e contenuta nel file depart.dtd, per esempio posto
allo stesso livello di depart.xml nel filesystem:
<?xml version="1.0" standalone="no"?> <!DOCTYPE departments SYSTEM "depart.dtd"> <departments> <title>Departments at the Politecnico di Milano</title> <department> <name> <italian>Architettura e Pianificazione - DiAP</italian> (<english>Architecture and Planning</english>) </name> <description> Analysis of urban dynamics and policies, analysis of changes in territory, Methods and techniques of town planning, Models of artificial intelligence in design and architecture, Planning of transports and territory, Ecological planning, Urban design. </description> Web site: <website><url>http://www.diap.polimi.it/</url> (<lang>in Italian</lang>)</website> </department> ... ... ... ... ... ... </department>
Le prime righe di depart.xml e il riferimento alla DTD esterna che lo valida. Notate che il documento non è più "standalone"
<!ELEMENT departments ( title, department* )> <!ELEMENT title ( #PCDATA )> <!ELEMENT department ( #PCDATA | name | description | website )*> <!ELEMENT name ( #PCDATA | italian | english )*> <!ELEMENT italian ( #PCDATA )> <!ELEMENT english ( #PCDATA )> <!ELEMENT description ( #PCDATA )> <!ELEMENT website ( #PCDATA | url | lang )*> <!ELEMENT url ( #PCDATA )> <!ELEMENT lang ( #PCDATA )>
La DTD esterna di depart.xml, salvata in un file di nome depart.dtd
Il linguaggio DTD è stato usato per anni con SGML quindi è ben collaudato e vi sono numerosi tool per processarlo, controllarlo e generarlo. Esistono diverse collezioni di DTD che potete scaricare dalla rete ed utilizzare (per es. da http://www.xml.org). Ogni DTD in effetti definisce un sottoinsieme di tutti gli infiniti possibili documenti XML che possono essere scritti, cioè quel sottoinsieme formato da tutti gli infiniti documenti XML che sono validi rispetto a quella DTD. Tale sottoinsieme viene detto "dialetto di XML". Per esempio MathML è un dialetto di XML adatto a descrivere espressioni matematiche anche molto complicate, sia allo scopo di essere renderizzate ad es. su un browser web che per essere elaborate da programmi di calcolo. Dal Febbraio 2001 MathML è una raccomandazione del W3C ed è già supportato da alcuni browser come Mozilla. Propongo di utilizzarlo nel caso di una eventuale prossima versione del nostro TOP test. Per ora abbiamo inserito nel TOP test le formule matematiche tramite immagini GIF ottenute catturando il rendering di un documento Latex e questo ha reso le pagine molto pesanti, un problema che invece MathML risolverebbe. Il browser editor del W3C Amaya permette già di comporre pagine HTML che contengono espressioni matematiche rappresentate direttamente in MathML tramite un equation editor di tipo WYSIWYG:
<math xmlns="http://www.w3.org/1998/Math/MathML">
<mrow>
<mi>F</mi>
<mo>=</mo>
<mi>G</mi>
<mfrac>
<mrow>
<mi>m</mi>
<mi>m</mi>
<mo>'</mo>
</mrow>
<msup>
<mi>r</mi>
<mn>2</mn>
</msup>
</mfrac>
</mrow>
</math>
|
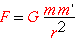 |
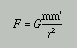 |
La legge di Newton della gravitazione universale scritta in MathML e renderizzata da Mozilla (a sinistra) e da Amaya (a destra).
Poichè Mozilla non supporta ancora la mistura di XML e HTML nello stesso
documento, il documento HTML deve avere estensione .xml
altrimenti l'elemento <math> non viene renderizzato.
Tuttavia un limite del linguaggio DTD è che non permette di definire
regole che forzino con precisione il contenuto dei tag: con DTD si può solo
stabilire che un elemento debba contenere una combinazione di testo libero o
altri tag (come l'elemento department nel DTD scritto prima),
oppure che debba essere vuoto, o contenere qualsiasi cosa, o solo una
determinata sequenza di elementi innestati ed eventualmente ripetuti più
volte (come ad es. avviene per la definizione dell'elemento radice
departments nell'esempio di prima), ecc... ma non c'è alcun modo per forzare
che il contenuto di un tag o di un attributo debba essere ad es. una data
espressa in un determinato formato o un numero intero o un valore "booleano"
del tipo vero/falso ecc... Nel nostro caso, non avendo noi necessità di
validazione molto stretta, ritengo che, almeno per ora DTD sia per noi più
che sufficiente e siccome è ancora molto diffuso vale comunque la pena di
usarlo e impararlo.
Esistono però anche altri linguaggi per la definizione di schemi di validazione, che oltre ad essere più potenti di DTD, hanno anche il vantaggio di essere sintatticamente espressi con la stessa sintassi di XML (sono cioè dei dialetti di XML, mentre DTD, che usa una sintassi differente, non lo è). I due più diffusi si chiamano XDR e XSD. Il fatto che anche lo schema sia espresso come un documento XML ha anche il vantaggio, oltre al fatto che non si deve imparare una nuova sintassi, di poter utilizzare gli stessi tool che si usano per sviluppare documenti XML anche per sviluppare e verificare i loro schermi (i tool che ho descritto finora sono: editor, parser non validanti, parser validanti), anziché usare tool differenti.
Lo standard XSD non è ancora molto maturo, tuttavia esistono già alcuni tool per convertire una DTD in un documento XSD, quindi anche se scegliamo di usare DTD, come per ora mi sento di consigliare, potremmo in futuro effettuare la conversione ad XSD in modo automatico o semi-automatico, semplicemente convertendo con un programma ogni DTD in XSD e poi raffinandola manualmente.
I sorgenti di questo paragrafo sono disponibili in:
Finora abbiamo visto come scrivere documenti XML e come forzare la
struttura ad albero di XML ad essere di un certo modo stabilito tramite le
regole del linguaggio DTD. Il passo successivo naturalmente è quello di
utilizzare XML per il rendering in un browser web. Un metodo consiste nel
collegare un foglio di stile CSS al documento XML e verrà esemplificato in
questo paragrafo. Un altro metodo consiste nello scrivere una specie di
script che trasformi XML in un altro linguaggio di formattazione del testo,
come HTML o PDF. Quest'ultimo metodo, limitatamente alle trasformazioni
XML->HTML, sarà descritto nel paragrafo dedicato a XSLT. In entrambi i
casi lo stile e il contenuto vengono completamente separati, al contrario di
quello che avviene con HTML dove esistono tag che descrivono sia il contenuto
che lo stile (ad es. <H1>). Perché separare il contenuto
dallo stile? In primo luogo perchè lo stesso documento XML oltre per il
rendering, può essere utilizzato anche per altri scopi, ad es. può essere
importato in un database che supporta XML. Quindi un documento XML si adatta
a molteplici usi, esattamente così com'è, senza alcuna necessità di modifiche
o conversioni.
Nota: il database server da noi utilizzato, MySQL, nella versione 4.X alpha permette solo
di fare il dump di un database come XML ben formato (opzione -X di
mysqldump). Invece di includere il supporto per XML all'interno
del database server, gli sviluppatori di MySQL, per mantenere efficiente e
semplice il server, hanno scelto di demandare alle applicazioni client del
database server (come mysqldump o PHP) il compito (piuttosto
semplice tra l'altro) di generare direttamente codice XML. Per importare un
documento XML in un database di MySQL occorrerà quindi ricorrere a script
appositi che utilizzano un parser XML (e che possono essere scritti ad es. in
PHP).
I fogli di stile CSS sono stati creati come un metodo per formattare le
pagine HTML senza dover usare tag di tipo presentazione (come
<I>, <B>, <FONT>
ecc..). Gli standard di riferimento sono il CSS1 e il CSS2 che è un superset di CSS1 con molte funzionalità in
più. Lo standard CSS1 è molto ben supportato, ad es. è supportato da
Microsoft Internet Explorer per Windows o Macintosh a partire dalla versione
3.0 e da Netscape Navigator per Windows a partire dalla versione 4.5.
Consiglierei perciò di limitarsi per ora allo standard CSS1.
CSS sta per Cascading Style Sheets, cioè "fogli di stile a cascata". Sono detti così perchè gli stili possono essere impostati a vari livelli e ogni livello può sovrapporre le proprie definizioni di stile su quelle precedenti; così gli stili in un file CSS esterno possono essere ridefiniti da un foglio di di stile interno al documento e a sua volta questi ultimi possono essere ridefiniti o rifiniti tramite stili in linea applicati ai singoli elementi.
Non tutti i browser però sono in grado di renderizzare la combinazione XML+CSS. Solo a partire dalla versione 6 Netscape supporta il rendering di XML via CSS ed Explorer solo a partire dalla versione 5.
Il foglio di stile seguente applica a depart.xml la stessa formattazione di depart.htm che abbiamo in linea:
/* style.css */
departments
{
display:block;
margin:0.5em 2em 0.5em 2em;
font-family:Arial,Helvetica,sans-serif
}
title
{ display:block;
width:19em;
color:#CCCCCC;
background-color:#666666;
padding:10px;
font-size:1.5em
}
department
{
display:block;
padding:0.8em;
background-color:#E8E8E8;
font-size:0.8em
}
name
{
display:block;
font-weight:bold
}
description
{
display:block
}
Si noti soprattutto come sono concise le regole di CSS rispetto
all'utilizzo delle tabelle e dei tag di presentazione come il tag
<FONT> e a tanti altri stupidi trucchi usati per ottenere
stili particolari in HTML.
<?xml version="1.0" standalone="no"?> <?xml-stylesheet type="text/css" href="style.css"?> <departments> <title>Departments at the Politecnico di Milano</title> ... ... ...Si noti l'aggiunta dell'istruzione di processo che collega il documento depart.xml al suo foglio di stile style.css
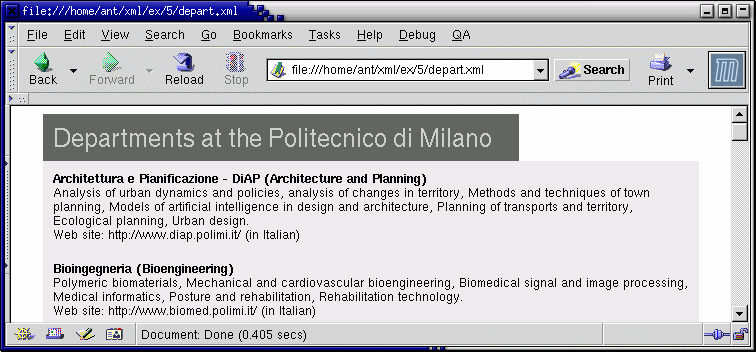
depart.xml renderizzato tramite un foglio CSS. Risultato identico a
depart.htm !
Probabilmente vi state chiedendo come si fa ad aggiungere un link tramite CSS. La risposta è che non si può. Nel paragrafo successivo dedicato ad XLink vedremo come aggiungere i link ai siti dei dipartimenti.
Un altro vantaggio evidente della separazione del contenuto dallo stile, oltre che la semplicità di manutenzione, è che è possibile effettuare il restyling del sito semplicemente cambiando i fogli di stile, senza dover mettere mano al documento XML. E' inoltre possibile creare più fogli di stile per uno stesso documento XML, differenziando ciascun foglio di stile in base al tipo di browser che si vuole supportare in modo ottimale. Si può quindi rilevare quale tipo di browser l'utente sta utilizzando, tramite tecniche lato client (generalmente è consigliabile JavaScript) oppure lato server e quindi linkare il documento XML ad un foglio di stile differente a seconda del tipo di browser del client. Ecco un esempio tramite PHP:
<?php
# attenzione impostare
# short_open_tag = Off
# in php.ini per poter
# mischiare codice XML e PHP
# da usare se xml non è impostato
# per default in php.ini:
# default_mimetype = "text/xml"
header('Content-Type: text/xml');
?>
<?xml version="1.0" standalone="no"?>
<?xml-stylesheet type="text/css" href="<?php
echo strstr($HTTP_USER_AGENT,'MSIE') ? 'msie.css' : 'netscape.css';
?>"?>
... ... ...
I sorgenti di questo paragrafo sono disponibili in ex/5/depart.xml e ex/5/style.css.
Il linguaggio HTML ha il tag <A> (anchor, cioè "tag
ancora") che permette di inserire in una pagina un link ad un'altra pagina o
risorsa multimediale. Questo piccolo tag è quello che ha fatto il web. Non
bisogna chiedere il permesso per inserire in una propria pagina il link alla
pagina di un altro. La potenzialità del web è dovuta in gran parte a questa
fitta di rete di collegamenti tra le milioni di pagine web presenti su
Internet.
Il meccanismo del tag <A> è unidirezionale, cioè
connette una singola risorsa ad una singola destinazione. Non è possibile
avere un singolo link che punti a destinazioni multiple. Inoltre la
definizione del link (cioè la locazione a cui punta il link) non può essere
separata dal sorgente (il file che contiene il link). In altre parole non è
possibile creare un link se non si possiede il permesso di scrittura nel file
sorgente.
XML Link Language (XLink) è la specifica raccomandata dal W3C per le
funzioni di linking in XML. E' molto più potente del tag
<A> e permette di superare tutte le limitazioni a cui
accennavo pocanzi.
Nonostante XLink sia molto potente, le implementazioni non sono ancora
molto diffuse. Internet Explorer allo stato attuale non ha alcun supporto per
XLink, mentre Mozilla supporta solo i link semplici. Perciò io sarò un po'
bifolco ed userò XLink nell'esempio seguente per creare dei semplici link del
tipo di quelli che si possono creare col tag <A> di HTML.
Questo non rende ragione della potenza di XLink però almeno esemplifica il
fatto che XLink mantiene la compatibilità con i costrutti di linking di
HTML4.
<?xml version="1.0"?>
<?xml-stylesheet type="text/css" href="style.css"?>
<departments xmlns:xlink="http://www.w3.org/1999/xlink">
<title>Departments at the Politecnico di Milano</title>
<department>
<name>
<italian>Architettura e Pianificazione - DiAP</italian>
(<english>Architecture and Planning</english>)
</name>
<description>
Analysis of urban dynamics and policies, analysis of changes in territory,
Methods and techniques of town planning, Models of artificial intelligence
in design and architecture, Planning of transports and territory,
Ecological planning, Urban design.
</description>
Web site: <website><url xlink:type="simple"
xlink:href="http://www.diap.polimi.it/">http://www.diap.polimi.it/</url>
(<lang>in Italian</lang>)</website>
</department>
... ... ...
Aggiungiamo dei semplici link ai siti dei dipartimenti tramite
XLink
url
{
text-decoration:underline;
color:blue;
}
La rule CSS da aggiungere a style.css
Si noti come XLink è implementato nella forma di attributi sugli elementi,
sicchè ogni elemento in XML può fungere da link (mentre in HTML solo il tag
<A> crea un link). La rule CSS da aggiungere a style.css
stabilisce che i link devono essere sottolineati e di colore blu, come è
usuale per poterli distinguere facilmente.
I sorgenti di questo paragrafo sono disponibili in ex/6/depart.xml e ex/6/style.css.
Finora, per cercare di snellire il lavoro dell'ufficio SIWA e ridurre i tempi di attesa per l'aggiornamento delle informazioni del sito, abbiamo costruito dei back-end con gli strumenti offerti da HTML, dallo scripting lato server (usando i linguaggi Perl, C e soprattutto PHP) e dai database server relazionali (MySQL). Lo scopo è quello di permettere ad altri uffici di aggiornare autonomamente alcune informazioni presenti nel sito. In questo modo abbiamo diminuito un po' il lavoro del SIWA ed eliminato alcune perdite di tempo dovute alla comunicazione umana (orale o scritta) delle modifiche che devono essere effettuate tra ogni ufficio che gestisce le informazioni e il SIWA stesso. L'utilizzo dei backend non richiede particolari conoscenze di HTML, ma solo una pratica elementare nella navigazione web, ed è quindi alla portata anche del personale non strettamente tecnico.
Il problema con i back-end è che non sono facilmente modificabili ed estendibili: per poter apportarvi anche alcune semplici modifiche o estensioni è sempre richiesta la conoscenza di HTML e non solo: occorre anche conoscere il linguaggio di scripting che è stato usato in combinazione con l'HTML per l'implementazione del back-end e poi persino le particolarità del db server usato.
Inoltre un back-end scritto in HTML generato lato server non può fare più di quello per cui è stato progettato e non potrà mai avere la flessibilità e tutte le funzionalità di un editor HTML; ad es. non c'è un modo semplice per permettere all'utente di un back-end che ignori HTML di poter applicare alcune delle formattazioni più comuni ad un determinato testo. Spesso per raggiungere almeno in parte questo scopo abbiamo fatto sì che gli utenti possano inserire codice HTML in alcuni campi testo delle tabelle dei database relazionali. Per questo scopo abbiamo utilizzato spesso dei controlli JavaScript che inseriscono l'HTML per l'utente. Un altro sistema possibile per permettere ad un utente che non conosce HTML di inserire alcune formattazioni tramite un back-end, potrebbe essere quello dell'invenzione di un altro linguaggio di markup, molto più semplice di HTML, che l'utente del back-end deve imparare e poi utilizzare per i suoi limitati scopi di formattazione.
Anche se queste soluzioni risolvono in parte il problema, presentano alcuni inconvenienti: nel primo caso occorre memorizzare il codice HTML insieme ai dati nei campi delle tabelle del database; nel secondo caso si deve memorizzare nel database un codice di markup più semplice di HTML, magari anche meno prolisso, ma poi bisognerà convertirlo in HTML prima di poterlo inviare al browser (questo complicato sistema viene largamente usato da alcuni back-end per la realizzazione di forum via web che proprio in tal modo mettono a disposizione di alcuni utenti una limitata capacità di formattazione dei messaggi che essi inviano).
In entrambi i casi quindi si appesantisce la mole dei dati presenti nel database, che invece dovrebbe essere del tutto indipendente dalla sua rappresentazione grafica, in modo da potersi prestare ad utilizzi potenzialmente differenti. Inoltre si tratta comunque di sistemi piuttosto complicati o limitati nelle loro capacità.
Un sistema molto meno limitato per permettere all'utente di un back-end alcune possibilità di formattare il testo che inserisce o modifica, consiste nell'utilizzo di editor tipo WYSIWYG integrati nelle pagine web, scritti in Java oppure sotto forma di oggetti COM da istanziare tramite JavaScript o VBScript . La qualità dell'HTML generato da questi tool tuttavia è solitamente molto dubbia e nel caso degli oggetti COM ovviamente la portabilità è molto limitata e comunque anche in tal caso occorre far finire il codice HTML come parte dei dati nel database. Inoltre questi editor html WYSIWYG incorporabili nelle pagine web non hanno tutte le funzionalità e la stabilità di un vero e proprio programma editor HTML.
I vantaggi della separazione del contenuto dallo stile che si possono attuare completamente solo mediante l'adozione di XML sono molteplici. Da questa separazione deriva soprattutto leggibilità, facilità di editing, facilità di restyling e di stampa. Leggibilità e facilità di editing si ha perchè quando interessa editare i contenuti si guarda all'XML e quando interessa cambiare lo stile si guarda al foglio di stile CSS o di tipo XSL. Quando si vogliono editare i contenuti non ci si deve preoccupare dello stile (non si devono inserire tag di presentazione come avviene con HTML) e viceversa. Anche chi è completamente all'oscuro di CSS o XSL può apportare modifiche ai contenuti di un sito editando, anche tramite editor ad hoc molto facili da usare, il solo codice XML della pagina. L'editing di XML richiede in effetti conoscenze minime, mentre lo stesso non si può dire con HTML. Inoltre la validazione previene gli errori. La facilità di restyling si ha perchè essendo i contenuti e lo stile separati, si possono facilmente generare più versioni (es. testuale, grafica semplice che supporti browser anche un po' vecchiotti o grafica complessa che supporti il browser all'ultimo grido, WAP per i telefonini, ecc..). Quando si vogliono generare più versioni grafiche usando come unico strumento HTML, si è costretti a ripetere l'editing dei contenuti in ciascuna versione - una cosa piuttosto seccante e soggetta ad errori. Invece con XML basta editare il solo documento XML. La facilità di stampa si ottiene perchè tramite l'utilizzo di fogli di stile XSL-FO è possibile generare automaticamente anche la versione in PDF di una pagina web.
Tutto il know-how che abbiamo acquisito (soprattutto PHP, HTML) non va perduto: per utilizzare XML+XSLT, che verrà esemplificato nel paragrafo successivo, occorre ovviamente conoscere HTML. PHP e i database relazionali possono essere ancora utilizzati dove necessari: la differenza è che dal codice PHP si produce codice XML anziché HTML, e la formattazione viene applicata con un foglio di stile esterno (CSS oppure XSLT). Finora abbiamo cercato di separare l'HTML dal codice PHP tramite l'utilizzo di semplici librerie template (vedere ad es. http://www.phpguru.org/template.html), ma queste librerie presentano alcune limitazioni, a causa delle quali spesso non si può avere una separazione completa tra codice PHP o HTML o non la si può attuare in modo semplice . XML+XSLT permette invece di separare i contenuti dallo stile ed offre molta più flessibilità di qualsiasi libreria che tenta semplicemente di separare codice PHP da codice HTML. Quindi XML sarà un grosso vantaggio, non solo per le pagine statiche, ma anche per quelle dinamiche: è più facile per il programmatore produrre codice XML da PHP, perchè è meno prolisso di HTML e può essere controllato tramite le DTD; per il webmaster è più facile e sicuro modificare lo stile delle pagine, senza dover ricorrere all'aiuto del programmatore, perchè la "grafica" è separata dai contenuti generati dinamicamente. I database andranno usati solo quando ci sono molti record: quando i record sono pochi e non ci sono complicate necessità di querying (visto che XML Query non è ancora abbastanza maturo nel momento in cui scrivo) non è conveniente ricorrere ai database relazionali ed i dati andrebbero rappresentati direttamente in XML.
Per concludere questo paragrafo credo che dovremmo spendere energie per l'utilizzo di XML sull'intero sito del Politecnico di Milano o almeno su quelle sezioni che vengono modificate più spesso o che decidiamo di far modificare a personale non tecnico. XML è il futuro del web, un futuro che non è una profezia perché è stato già deciso dal W3C. Ci sono già molti ottimi tool per lavorare con XML. I maggiori browser lo supportano sempre meglio. Sono convinto che un progetto futuro di rifacimento e miglioramento del nostro sito non può non tenere conto di XML. XML apre molte nuove possibilità per un migliore e più efficiente uso, interpretazione e scambio dei dati. XML darà definitivamente molto più valore ai nostri dati. Usare XML significa sia trarne vantaggi subito che essere poi subito pronti per il web del futuro.
XSLT (XSL Transformation Language) è un linguaggio, espresso nella forma sintattica di XML, che permette di stabilire delle regole per la trasformazione di una struttura ad albero XML ben formata in un'altra struttura ad albero XML, e anch'essa deve essere ben formata. Si ricordi che un documento HTML ben formato è a tutti gli effetti anche un documento XML ben formato, quindi si può produrre HTML a partire da XML tramite XSLT. XSLT è un vero e proprio linguaggio di programmazione, ma di tipo particolare: è dichiarativo, basato sulle regole e guidato da eventi e sintatticamente è scritto come un dialetto di XML.
Per terminare il nostro esempio con la pagina del sito inglese, scriviamo un foglio XSLT per trasformarla da XML ad HTML. Per prima cosa miglioriamo il codice XML introducendo l'uso di attributi, elimando tutto il testo che fa parte della presentazione (come ad es. la stringa "Web site: "), riscriviamo in modo più restrittivo la relativa DTD e inseriamo l'istruzione di processo che collega il foglio XSL e la DTD, che abbiamo scelto di inserire come esterna. Il risultato è il file XML non standalone ben formato e valido di cui viene riportata di seguito la prima parte e la relativa DTD esterna:
<?xml version="1.0" standalone="no"?> <?xml-stylesheet type="text/xsl" href="depart.xsl"?> <!DOCTYPE departments SYSTEM "depart.dtd"> <departments> <title>Departments at the Politecnico di Milano</title> <department> <name> <italian>Architettura e Pianificazione - DiAP</italian> <english>Architecture and Planning</english> </name> <description> Analysis of urban dynamics and policies, analysis of changes in territory, Methods and techniques of town planning, Models of artificial intelligence in design and architecture, Planning of transports and territory, Ecological planning, Urban design. </description> <website url="http://www.diap.polimi.it/" lang="ita" /> </department> ... ... ...La nuova versione di depart.xml che ora è più XML-like
<!ELEMENT departments ( title, department* )>
<!ELEMENT title ( #PCDATA )>
<!ELEMENT department ( name, description, website )>
<!ELEMENT name ( italian, english )>
<!ELEMENT italian ( #PCDATA )>
<!ELEMENT english ( #PCDATA )>
<!ELEMENT description ( #PCDATA )>
<!ELEMENT website EMPTY>
<!ATTLIST website
url CDATA #REQUIRED
lang ( ita | eng | both ) #REQUIRED>
La DTD che valida il documento XML precedente. È stato scelto di
rendere obbligatori gli attributi url e lang
Voglio mostrare i dettagli di come a partire da un documento HTML non ben formato quale depart.htm si può convertirlo in XML+XSLT che produce HTML ben formato e possibilmente anche valido. In pratica si tratta di ripulire il documento HTML manulamente oppure usando Tidy. Il risultato viene salvato in depart.xsl e ovviamente non è ancora un documento XSL valido, bensì un documento XML o meglio HTML ben formato e valido (se non contiene errori semantici o tag proprietari). Si tratta poi di intercalare in depart.xsl le regole di XSLT attorno a pezzi opportuni di codice HTML e di eliminare del codice HTML ripetitivo che viene generato ora automaticamente tramite un processo di iterazione XSLT.
bash-2.05$ cp depart.htm depart.xsl bash-2.05$ tidy --output-xml true -m depart.xsl Can't open "/home/ant/.tidyrc" Tidy (vers 4th August 2000) Parsing "depart.xsl" line 12 column 1 - Warning: <table> lacks "summary" attribute line 74 column 12 - Warning: replacing illegal character code 146 line 83 column 16 - Warning: replacing illegal character code 146 line 152 column 25 - Warning: discarding unexpected </font> line 213 column 28 - Warning: missing </font> before </p> line 214 column 10 - Warning: inserting implicit <font> line 219 column 1 - Warning: trimming empty <center> line 222 column 1 - Warning: trimming empty <center> line 227 column 1 - Warning: trimming empty <center> depart.xsl: Document content looks like HTML proprietary 9 warnings/errors were found! Characters codes for the Microsoft Windows fonts in the range 128 - 159 may not be recognized on other platforms. You are instead recommended to use named entities, e.g. ™ rather than Windows character code 153 (0x2122 in Unicode). Note that as of February 1998 few browsers support the new entities. The table summary attribute should be used to describe the table structure. It is very helpful for people using non-visual browsers. The scope and headers attributes for table cells are useful for specifying which headers apply to each table cell, enabling non-visual browsers to provide a meaningful context for each cell. For further advice on how to make your pages accessible see "http://www.w3.org/WAI/GL". You may also want to try "http://www.cast.org/bobby/" which is a free Web-based service for checking URLs for accessibility. You are recommended to use CSS to specify the font and properties such as its size and color. This will reduce the size of HTML files and make them easier maintain compared with using <FONT> elements. HTML & CSS specifications are available from http://www.w3.org/ To learn more about Tidy see http://www.w3.org/People/Raggett/tidy/ Please send bug reports to Dave Raggett care of <html-tidy@w3.org> Lobby your company to join W3C, see http://www.w3.org/ConsortiumCreiamo una copia "pulita" tramite Tidy di depart.htm da usare come base di partenza per la scrittura di depart.xsl
Tidy potrebbe non riuscire a ripulire completamente il documento HTML.
Occorre riguardarlo manualmente. Tuttavia un trucco per migliorarlo
ulteriormente è di effettuare più passate di Tidy, finché non vengono
rilevati più errori: nell'esempio, la seconda passata ha eliminato altri tag
<font> e <b> vuoti o ridondanti.
$ tidy --output-xml true -m depart.xsl Can't open "/home/ant/.tidyrc" Tidy (vers 4th August 2000) Parsing "depart.xsl" line 14 column 1 - Warning: <table> lacks "summary" attribute line 21 column 17 - Warning: trimming empty <font> line 21 column 24 - Warning: trimming empty <b> line 39 column 17 - Warning: trimming empty <font> line 43 column 17 - Warning: trimming empty <font> line 43 column 24 - Warning: trimming empty <b> line 57 column 17 - Warning: trimming empty <font> line 61 column 17 - Warning: trimming empty <font> line 61 column 24 - Warning: trimming empty <b> line 79 column 26 - Warning: trimming empty <font> line 84 column 17 - Warning: trimming empty <font> line 84 column 24 - Warning: trimming empty <b> line 95 column 26 - Warning: trimming empty <font> line 100 column 17 - Warning: trimming empty <font> line 100 column 24 - Warning: trimming empty <b> line 111 column 26 - Warning: trimming empty <font> line 116 column 17 - Warning: trimming empty <font> line 116 column 24 - Warning: trimming empty <b> line 126 column 26 - Warning: trimming empty <font> line 131 column 17 - Warning: trimming empty <font> line 131 column 24 - Warning: trimming empty <b> line 142 column 26 - Warning: trimming empty <font> line 147 column 17 - Warning: trimming empty <font> line 147 column 24 - Warning: trimming empty <b> line 162 column 26 - Warning: trimming empty <font> line 167 column 17 - Warning: trimming empty <font> line 167 column 24 - Warning: trimming empty <b> line 177 column 26 - Warning: trimming empty <font> line 182 column 17 - Warning: trimming empty <font> line 182 column 24 - Warning: trimming empty <b> line 195 column 26 - Warning: trimming empty <font> line 205 column 26 - Warning: trimming empty <font> line 210 column 17 - Warning: trimming empty <font> line 210 column 24 - Warning: trimming empty <b> line 218 column 26 - Warning: trimming empty <font> line 223 column 17 - Warning: trimming empty <font> line 223 column 24 - Warning: trimming empty <b> line 228 column 49 - Warning: trimming empty <font> line 233 column 26 - Warning: trimming empty <font> line 238 column 17 - Warning: trimming empty <font> line 238 column 24 - Warning: trimming empty <b> line 246 column 26 - Warning: trimming empty <font> line 259 column 26 - Warning: trimming empty <font> line 264 column 17 - Warning: trimming empty <font> line 264 column 24 - Warning: trimming empty <b> line 275 column 26 - Warning: trimming empty <font> line 280 column 17 - Warning: trimming empty <font> line 280 column 24 - Warning: trimming empty <b> line 293 column 26 - Warning: trimming empty <font> line 298 column 17 - Warning: trimming empty <font> line 298 column 24 - Warning: trimming empty <b> line 308 column 26 - Warning: trimming empty <font> line 313 column 17 - Warning: trimming empty <font> line 313 column 24 - Warning: trimming empty <b> line 327 column 26 - Warning: trimming empty <font> line 332 column 17 - Warning: trimming empty <font> line 332 column 24 - Warning: trimming empty <b> line 352 column 37 - Warning: trimming empty <font> line 352 column 44 - Warning: trimming empty <font> line 352 column 51 - Warning: trimming empty <p> depart.xsl: Document content looks like HTML proprietary 60 warnings/errors were found! The table summary attribute should be used to describe the table structure. It is very helpful for people using non-visual browsers. The scope and headers attributes for table cells are useful for specifying which headers apply to each table cell, enabling non-visual browsers to provide a meaningful context for each cell. For further advice on how to make your pages accessible see "http://www.w3.org/WAI/GL". You may also want to try "http://www.cast.org/bobby/" which is a free Web-based service for checking URLs for accessibility. You are recommended to use CSS to specify the font and properties such as its size and color. This will reduce the size of HTML files and make them easier maintain compared with using <FONT> elements. HTML & CSS specifications are available from http://www.w3.org/ To learn more about Tidy see http://www.w3.org/People/Raggett/tidy/ Please send bug reports to Dave Raggett care of <html-tidy@w3.org> Lobby your company to join W3C, see http://www.w3.org/ConsortiumLa seconda passata di Tidy su depart.xsl elimina molti tag inutili
$ tidy --output-xml true -m depart.xsl Can't open "/home/ant/.tidyrc" Tidy (vers 4th August 2000) Parsing "depart.xsl" line 14 column 1 - Warning: <table> lacks "summary" attribute depart.xsl: Document content looks like HTML proprietary 1 warnings/errors were found! The table summary attribute should be used to describe the table structure. It is very helpful for people using non-visual browsers. The scope and headers attributes for table cells are useful for specifying which headers apply to each table cell, enabling non-visual browsers to provide a meaningful context for each cell. For further advice on how to make your pages accessible see "http://www.w3.org/WAI/GL". You may also want to try "http://www.cast.org/bobby/" which is a free Web-based service for checking URLs for accessibility. You are recommended to use CSS to specify the font and properties such as its size and color. This will reduce the size of HTML files and make them easier maintain compared with using <FONT> elements. HTML & CSS specifications are available from http://www.w3.org/ To learn more about Tidy see http://www.w3.org/People/Raggett/tidy/ Please send bug reports to Dave Raggett care of <html-tidy@w3.org> Lobby your company to join W3C, see http://www.w3.org/ConsortiumLa terza e ultima passata di Tidy rileva che non ci sono più errori, solo qualche tago attributo proprietario (come l'attributo bordercolor) e la mancanza dell'attributo
summary del tag
<table>
Nonostante l'ultima passata non rileva errori, ci sono ancora delle ridondanze che ho dovuto rimuovere manualmente ed inoltre ho dovuto riorganizzare l'annidamento di molti tag per limitare il numero dei tag usati. Poi manualmente ho rimosso il tag <meta> perché ora non viene più usato il set di caratteri iso-8859-1, ma viene usato il set ASCII standard e i caratteri con codice >127 (i caratteri ASCII estesi) vengono resi tramite entità numeriche, come ritengo sia più appropriato. La versione finale pulita di depart.xsl è la seguente e sinceramente devo dire che spesso si fa prima a riscrivere l'HTML daccapo, piuttosto che cercare di ripulire quello generato da un tool WYSIWYG, ma ho voluto mostrare questo percorso di pulizia proprio per mettere in evidenza i vari problemi che presenta l'HTML non ben formato e pieno di ridondanze.
Credo che questo esempio, che tra l'altro si basa su una pagina molto semplice, mostri come sia desiderabile che tutti i nostri documenti HTML, sia generati tramite XML, sia prodotti con altri tool, siano, se non validi, almeno ben formati e privi di inutili ridondanze e possibilmente ben indentati. Dobbiamo spendere più tempo per curare meglio l'HTML che produciamo ed evitare l'uso di strumenti WYSIWYG che producono HTML di bassa qualità o almeno integrarlo con l'uso di strumenti di controllo e pulizia come Tidy. Non è sufficiente verificare che la pagina abbia una buona resa in un paio dei browser più usati, perchè i browser sono molto permissivi ed accettano di buon grado anche del cattivo codice HTML, ma non lo stesso si può dire dei parser XML: un parser XML si rifiuta di elaborare un documento HTML se non è ben formato. Quindi se produciamo documenti HTML ben formati, ci prepariamo fin d'ora al futuro che sarà tutto basato su XML.
Anche se XSLT può essere usato per trasformare un documento XML in un altro documento XML, e la cosa può essere molto utile quando si usa XML come formato di interscambio di dati, il caso più interessante sul web, almeno per ora, è naturalmente quello delle trasformazioni XML->HTML. Infatti utilizzando un processore XSLT lato server è possibile continuare a supportare browser anche molto antichi, che non gestiscono il rendering di XML+CSS o le trasformazioni XSLT lato client. Questo significa che un sito può usare XML con tutti i vantaggi che comporta (come abbiamo visto nel paragrafo precedente) senza che praticamente gli utenti del sito se ne accorgono: il browser riceve sempre codice HTML e non ha modo di sapere come questo codice HTML è stato ottenuto; il codice HTML potrebbe essere stato scritto direttamente come HTML e memorizzato staticamente sul server, oppure generato una tantum da una trasformazione XSLT o generato, sempre tramite XSLT, ad ogni richiesta.