rappresentazione schematica e diagrammi di flusso delle primitive di un semaforo mutex
| Introduzione ai sistemi operativi con UNIX | ||
|---|---|---|
| Prec | 6. La comunicazione tra i processi | Succ |
Abbiamo già detto molto sui semafori nei due paragrafi precedenti, ma credo sia meglio ribadire ancora una volta questi concetti, vedendo meglio la genesi del concetto di semaforo, come strumento alternativo al busy waiting.
Il problema più semplice che ci aveva portati all'introduzione dei semafori è quello della mutua esclusione: due processi (o più nel caso generale) vogliono utilizzare entrambi una stessa risorsa hardware o software, ma questa può essere usata dai processi solo in modo mutuamente esclusivo affinchè l'elaborazione avvenga correttamente. Ad esempio da una stampante che venga utilizzata in modo concorrente, uscirebbe una stampa errata in cui sono mischiate linee di documenti diversi. Lo stesso accadrebbe se due processi cercano di scrivere concorrentemente sullo stesso file, o entrambi cercano di captare i movimenti del mouse o di scrivere sul monitor.
Le sezioni di codice in cui i due processi accedono alla risorsa considerata sono dette sezioni critiche.
Una soluzione semplice a questo problema sarebbe quella di associare alla risorsa un flag (un bit) condiviso che indica se la risorsa è libera (valore 1 per convenzione) o occupata (valore 0). Dopodiché definiamo due operazioni primitive che operano su questo bit, chiamiamole lock() e unlock():
void lock(int *x)
{ while (*x!=1);
*x=0;
}
void unlock(int *x)
{ *x=1;
}
lock(&x);
/*
sezione critica
*/
unlock(&x);
La lock() la chiamiamo prima di accedere alla risorsa: se la risorsa è occupata (x==0) la lock() entra in un ciclo di attesa, testando in continuazione il valore di x, finchè non trova che x è stato cambiato in 1 da un altro processo, ossia che la risorsa si è liberata. Subito dopo pone 0 in x ad indicare che la risorsa è occupata. Il processo esegue quindi la sua sezione critica e poi esegue unlock() che semplicemente pone 1 in x per indicare che la risorsa è libera.
Questa tecnica è quella che comunemente si chiama busy waiting (o attesa attiva o ciclo di attesa attiva). Il busy waiting funziona in un sistema multiprogrammato, ad es. time-sharing, ma funziona molto male in pratica e deve essere sempre evitato se possibile. Infatti stiamo impegnando inutilmente la CPU quando un processo va nel ciclo di attesa e ci rimane per tutto il suo quanto di tempo, mentre potrebbero esserci altri eventuali processi pronti ad andare in esecuzione che fanno cose più utili che l'attesa attiva. Così stiamo sprecando quanti di tempo nell'attesa attiva.
Inoltre, così com'è, la lock() presenta un altro problema: supponiamo che un processo p1 abbia eseguito la lock(), sia appena uscito dal ciclo while (il ciclo di busy waiting) e capita che scade il suo quanto di tempo, prima che possa eseguire l'istruzione *x=0. Supponiamo ancora di essere così sfortunati che lo schedulatore decida di riprendere l'esecuzione di un altro processo p2 che esegua la lock() proprio per la stessa risorsa per cui l'aveva eseguita p1, cioè usando come parametro la stessa variabile condivisa x. Supponiamo che questo processo abbia il tempo di terminare l'esecuzione della lock() (che trova x==1 e la pone subito a 0) e di avviare la sua sezione critica, ma non di terminarla, perchè ad esempio la sezione critica di p2 richiede molto più del suo quanto di tempo. Ancora supponiamo che venga ripresa l'esecuzione di p1; l'esecuzione riprende dal punto in cui era stata interrotta, ossia da *x=0. Poi si esce da lock() e viene eseguita la sezione critica di p1. Ecco che le sezioni critiche di p1 e p2 sono eseguite concorrentemente.
Per evitare questo problema occorre che la lock() e la unlock() non possano essere interrotte. Questo si può ottenere solo con meccanismi hardware. Se i due processi p1 e p2 girano entrambi sulla stessa CPU, basta disabilitare le interruzioni di questa CPU all'inizio di ciascuna delle procedure e riabilitarle alla fine, prima del ritorno. Per la unlock(), se la sua unica istruzione *x=1 corrisponde ad una singola istruzione di macchina, come molto probabile, questa misura non è necessaria, essendo una singola istruzione di macchina non interrompibile, quindi sarà necessario farlo solo per la lock(). Nell'architettura i386 le interruzioni hardware si disabilitano tramite l'istruzione di macchina CLI (Clear Interrupt Flag) e si riabilitano tramite la STI (Set Interrupt Flag).
C'è persino un modo di scrivere la lock che la rende atomica, senza necessità di ricorrere alla CLI e alla STI. L'istruzione di macchina BTR (Bit Test and Reset) fa al caso nostro. Descriviamola usando per l'assembly i386 la sintassi AT&T, comune in UNIX. Essa ha due operandi, il primo è l'operando sorgente che può essere un byte immediato (memorizzato come parte dell'istruzione nello spazio codice) o un registro generale che indica su quale bit lavorare (i bit sono numerati da sinistra verso destra a partire da 0 per convenzione). Nel nostro caso scegliamo di usare il primo bit, quindi questo operando sarà 0. Siccome nella sintassi AT&T gli operandi immediati vanno preceduti da $, scriveremo $0. Il secondo operando della BTR è quello di destinazione e può essere un registro generale (nella sintassi AT&T il nome del registro va preceduto da un %) o un riferimento alla memoria.
La semantica della BTR è la seguente: in una sola operazione, non interrompibile, assegna il valore del bit selezionato al flag di riporto (CF o Carry Flag), operazione quest'ultima detta di Test del bit, e poi cambia questo bit in 0, operazione detta di Reset o Clear del bit. Questo spiega anche perchè la BTR è chiamata così (Bit Test and Reset).
La versione in linguaggio macchina della lock() che non presenta problemi di interruzione ottenuta tramite la BTR assomiglierà alla seguente:
lock: btr $0, x ;atomica jnc lock ret unlock: mov $1, x ;atomica ret
L'istruzione JNC (Jump if Not Carry) salta alla locazione di memoria codice corrispondente all'etichetta lock se il valore del flag di riporto CF è 0, altrimenti si esce dalla funzione lock() e si ritorna al chiamante usando un'istruzione tipo la RET (Return From Procedure).
Si noti che la sezione critica non è necessario che sia tutto il corpo della procedura lock(), ma solo le azioni corrispondenti alla btr. Siccome la btr è una singola istruzione di macchina, ne è assicurata l'atomicità. In altri termini non ci sono problemi se il processo viene sospeso prima o dopo l'esecuzione della btr anche se siamo nel mezzo della procedura lock().
Inoltre notare che se la btr trova che x vale 0, ci riscrive 0 e la jnc salterà (polling), ripetendo il test and clear (ciclo di polling) finché la btr trova che x vale 1 e anche in tal caso lo pone a zero. Il valore 1 viene salvato nel CF, quindi la jnc non salta e la lock() termina e il processo invocante proseguirà con l'esecuzione della sezione critica, avendo acquisito la risorsa.
Quindi abbiamo trovato una soluzione piuttosto semplice al problema della mutua esclusione, usando il busy waiting, ma purtroppo è inefficiente. Possiamo risolvere lo stesso problema in modo più efficiente, eliminando il polling, al costo di complicare leggermente le primitive lock() e unlock()? La risposta è sì e la conoscete già: le primitive lock() e unlock() migliorate diventano rispettivamente le primitive wait() e signal() e oltre alla x occorre introdurre una coda per formare una struttura più complessa che viene chiamata semaforo (nel caso del problema della mutua esclusione tra due soli processi, la coda può essere ridotta ad un solo elemento). Ne ripetiamo ancora una volta la definizione.
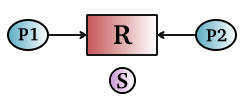
Un semaforo binario protegge una risorsa da accessi concorrenti. e risolve in modo efficiente in un ambiente multiprogrammato il problema della mutua esclusione: il processo p1 e p2 vogliono acquisire entrambi una risorsa, ma questa può essere usata dai processi solo in modo mutuamente esclusivo. La risorsa è guardata allora da un semaforo che inizialmente vale 1, per indicare lo stato di risorsa libera. Il valore del semaforo binario è infatti un indicatore che indica se la risorsa è libera (1) o occupata (0), proprio come la x della lock() e unlock().
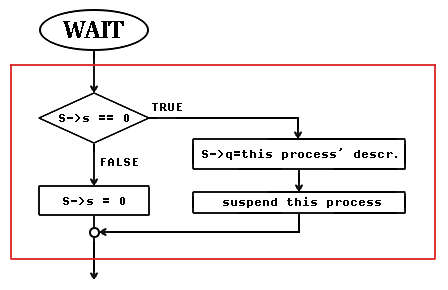
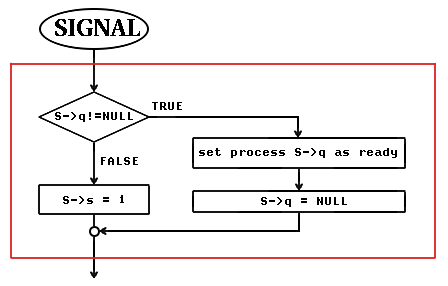
Le due primitive che agiscono sul semaforo hanno i seguenti diagrammi di flusso:
rappresentazione schematica e diagrammi di flusso delle primitive
di un semaforo mutex
In generale, anche per semafori non binari, la definizione C è del tipo della seguente:
struct semaphore
{ unsigned int s; /* valore del semaforo */
struct descriptorQueue q; /* coda dei processi bloccati */
}
dove il tipo descriptorQueue contiene due puntatori alla tabella
dei descrittori (un array della struttura descriptor, con
dimensione pari al massimo numero di processi fissato per il
sistema). Stiamo supponendo che ogni descrittore contenga un
puntatore al successivo descrittore nella coda. Per gestire una
lista linkata con politica FIFO in modo efficiente conviene
conservarsi di volta in volta il riferimento sia al primo che
all'ultimo elemento della coda, perchè da una parte bisogna
inserire e dalla parte opposta occorre prelevare. Perciò la
struttura descriptorQueue sarà di questo tipo:
struct descriptQueue
{ struct descriptor *first, *last;
}
Notate che se c'è almeno un processo in coda su un semaforo, il contatore del semaforo deve essere zero (o come si dice "rosso"), perché altrimenti non ci potrebbe essere un processo in coda. Il viceversa non è sempre vero, cioè se il semaforo è rosso, non è detto che ci siano processi in coda, la coda potrebbe essere anche vuota, esattamente come può capitare con un semaforo stradale in un momento di mancanza di traffico.
Quando il processo viene risvegliato (riattivato), il semaforo è uguale a zero e non appena questo processo ricomincia a fare uso della CPU, esce dalla wait() che lo aveva bloccato ed entra direttamente nella sezione critica (la sua prima istruzione dopo la wait()).
La signal() viene chiamata da un processo che ha terminato la sua sezione critica. Quando la signal() riattiva un altro processo, il semaforo rimane uguale a zero. Era zero perchè il processo che ha chiamato la signal() aveva eseguito la wait() senza mai bloccarsi, oppure si era bloccato sulla wait() ma poi è uscito dal blocco con semaforo uguale a zero, perché abbiamo appena detto che quando si esce dal blocco il semaforo rimane a 0, perché la risorsa rimane occupata, è stata infatti appena assegnata a questo processo che ha ripreso ad essere eseguibile!
Tutte le operazioni dentro la cornice rossa devono essere eseguite senza interruzioni. La wait() è una sezione critica nei confronti delle variabili su cui opera (valore del semaforo e coda dei processi pronti). Lo stesso la signal(). Siccome la wait() e la signal() sono essi stessi strumenti di sincronizzazione, chi assicurerà la loro sincronizzazione? Si deve usare il meccanismo più brutale che elimina del tutto la possibilità che wait() e signal() siano eseguite concorrentemente: in un sistema con una sola CPU è sufficiente disabilitare le interruzioni durante l'esecuzione della wait() o della signal(). Questo è un meccanismo hardware che si rende necessario a livello della wait() e della signal(). È evidente infatti che sia la wait() che la signal() possono funzionare correttamente soltante nell'ipotesi che siano primitive non interrompibili e che, a meno che non esistano istruzioni di macchina che le implementino direttamente, cosa inusuale essendo operazioni di alto livello piuttosto complicate, non c'è altro modo per sincronizzarle nell'accesso al semaforo.
Tra l'altro tenete sempre presente che la wait() e la signal() sono primitive di nucleo: fanno parte del codice del kernel e sono invocate come interruzioni (system call) dai programmi di utente. Esse eseguono perciò in modo kernel (o "privilegiato"), sono procedure del kernel invocabili dai processi di utente. Le strutture semaforiche possono essere allocate in memoria privata del kernel. I programmi utente non hanno bisogno di accedervi direttamente, anzi non devono farlo perchrè potrebbero alterare lo stato del semaforo e renderlo inconsistente (oltre al problema della competizione nell'accesso); i programmi utente devono accedere ai semafori solo attraverso le primitive wait() e signal().
Ma cosa accade in un sistema multiprocessore (in cui più CPU che sono collegate ad un unico bus e possono avere memoria privata ma anche condividere della memoria comune)? In un sistema multiprocessore questa misura di disabilitare le interruzioni di una CPU è sufficiente solo se i due processi p1 e p2 operano sulla stessa unità di elaborazione. Se operano su CPU diverse, disabilitare le interruzioni della CPU che sta eseguendo la wait() o la signal() non assicura che queste non eseguano concorrentemente. La wait() e la signal() si possono ancora usare su sistemi con più processori, ma vanno modificate introducendo un certo busy waiting controllato. Non vedremo i dettagli, anche se la modifica è piuttosto semplice, ma ci tengo a sottolineare che così come le abbiamo scritte la wait() e la signal() sono strumenti di sincronizzazione che funzionano solo su macchine monoprocessore, del resto ancora oggi le più economiche e comuni.
Deve essere notato che sincronizzare dei processi ha un costo che può essere trascurabile rispetto ai benifici della multiprogrammazione, e solitamente lo è, ma è inevitabile e non è mai nullo: il cambio di contesto (passare dall'esecuzione di un processo ad un altro) prevede di salvare e ripristinare lo stato dei processi ed ha un costo; ma anche la wait() e la signal(), gli strumenti di sincronizzazione, per il solo fatto di essere eseguite, introducono un certo overhead.
L'overhead dipende dal calcolatore, dal fatto che abbia istruzioni hardware che facilitano l'implementazione della wait o signal altrimenti queste devono essere implementate completamente in software.
L'overhead è di solito accettabile, tranne nei rari casi in cui le sezioni critiche da eseguirsi sono molte e contemporaneamente la maggior parte di queste sono brevi. Cosa significa "sufficientemente brevi"? In un sistema time-sharing vogliamo dire che in media impiegano meno di un singolo quanto di tempo. In tal caso non conviene usare le wait e le signal e il semaforo associato, ma basta disabilitare e riabilitare le interruzioni (sempre in un sistema monoprocessore). In questo modo per un periodo di tempo breve tengo occupato il sistema su un solo processo (le sezioni critiche in tal caso non sono interrompibili, mentre con la wait e la signal lo erano).
È ovvio che sostituire la wait() e la signal() con una CLI e una STI rispettivamente quando le sezioni critiche impiegano mediamente molto tempo per eseguire o usare sempre la CLI e la STI invece di wait() e signal() sarebbe inefficiente perché disattiverebbe per lungo tempo i benefici della multiprogrammazione.
È compito del programmatore decidere caso per caso se conviene usare la wait() e la signal() o disabilitare le interruzioni, considerando come sono le sezioni critiche. Se sono veloci e semplici ed eseguibili quindi senza necessità di attendere qualche evento lento tipicamente in uno o pochi quanti di tempo, allora conviene usare la sincronizzazione forte (disabilitando le interruzioni durante la sezione critica), altrimenti meglio usare la wait() e la signal().
| Prec | Indice | Succ |
| Il problema del produttore-consumatore | Livello superiore | exit, _exit |