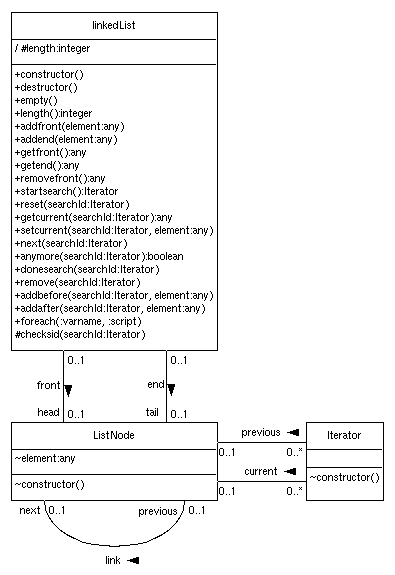
Class diagram generato dal sorgente tramite TCM
« Esempio: la classe pack • Appunti di Tcl/Tk • Esempio: un derivatore simbolico »
Affrontiamo adesso il progetto di una classe general-purpose un po' più complicata. Vogliamo creare un tipo astratto per creare e manipolare liste concatenate generiche.
Come abbiamo visto Il linguaggio Tcl come Lisp permette la manipolazione delle liste rappresentate sotto forma di stringhe. Perchè quindi vogliamo introdurre ancora un'altra implementazione del concetto di lista? La risposta sta nel problema dell'efficienza. Nel caso di liste corpose (da una certa dimensione in poi) e/o con singoli elementi che sono stringhe di notevole lunghezza, la rappresentazione tramite stringa non è più conveniente.
Le operazioni lindex per estrarre un elemento, llength per calcolare il numero di elementi, linsert per inserire un nuovo elemento, ed altre che sono già disponibili, nel caso peggiore dovranno scandire tutta la lista ed i suoi elementi, carattere per carattere. Per fare spazio poi ad un nuovo elemento che deve essere inserito, ad esempio in testa alla lista, tutti gli elementi successivi dovranno essere spostati, carattere per carattere. Lo stesso per la rimozione.
Le liste di stringhe di Tcl consentono di trattare le liste come fossero array, simulando l'accesso casuale tramite quello sequenziale. Questo è comodo e nel contempo efficiente solo per liste di piccole dimensioni, per cui l'accesso indicizzato introduce un overhead trascurabile.
La nostra implementazione, pur essendo scritta in [incr Tcl] piuttosto che in C, in pratica sarà molto più efficiente su liste grandi. La nostra interfaccia non prevede l'accesso indicizzato, ma solo quello sequenziale. Se trovate che state utilizzando una lista di grosse dimensioni e vi occorre l'accesso casuale, probabilmente è perchè avete sbagliato la scelta della struttura dati. Provate ad esempio ad usare un array associativo di Tcl invece di una lista.
L'accesso sequenziale rappresenta il modo più naturale di usare le liste e sfruttarne i vantaggi (che sono l'efficienza negli inserimenti e cancellazioni degli elementi). L'idea fondamentale della nostra interfaccia che supporta l'accesso sequenziale anziché quello casuale, è di permettere all'utilizzatore della classe di passare ai metodi per rimuovere o aggiungere un nodo o per modificarne il valore, l'informazione che indica la posizione corrente nella lista durante una scansione.
In generale vogliamo poter collegare in una lista non solo stringhe, ma variabili di tipo qualsiasi, quali le liste di stringhe built-in in Tcl, gli array, altri oggetti, oppure liste linkedList stesse, in modo da definire liste innestate (liste di liste, liste di liste di liste, ecc.)
Come si potrà ottenere questa generalità? L'elemento di una lista sarà semplicemente il nome di una variabile, ovvero una variabile stringa interpretata come un puntatore letterale. Lo stesso trucco di creare una lista di nomi di variabili anzichè di valori lo possiamo usare con le liste di stringhe incorporate in Tcl, in modo da renderle generiche. Da notare che la classe linkedList non sa niente sull'interpretazione che bisogna dare agli elementi della lista e non ha bisogno di saperlo: per quanto concerne linkedList, gli elementi della lista sono variabili scalari (stringhe Tcl) e niente di più. È l'applicazione che deve sapere come interpretare i valori degli elementi.
Le nostre liste anzichè essere rappresentate da singole stringhe, saranno rappresentate da più oggetti collegati tra loro. È questa la differenza fondamentale che permette di ottenere una migliore performance nel caso di grandi liste. Ciascun oggetto linkedList conterrà al proprio interno, come variabile membro, un oggetto di classe ListNode che indica il primo nodo (testa) della lista, un altro che indica l'ultimo nodo (coda), una variabile che tiene traccia della lunghezza della lista e i metodi per manipolare la lista. Un nodo della lista (ListNode) non è un elemento, ma contiene sia l'elemento sia il puntatore letterale al nodo successivo, che a sua volta contiene un altro elemento e il puntatore al nodo ancora successivo e così via, in quanto la lista è una struttura ricorsiva. Naturalmente una lista nella memoria finita di un calcolatore non può essere infinita: occorre quindi introdurre un discriminante per indicare la fine della lista.
La prima soluzione che viene in mente è di includere in ciascun ListNode un campo dati booleano che indica se le altre informazioni contenute nel nodo sono valide, oppure si tratta di un nodo fittizio che segnala la fine della lista.
Ci possiamo risparmiare il nodo finale fittizio se stabiliamo che il booleano indica se c'è o meno un nodo successivo, anzichè se il nodo corrente è un nodo fittizio finale oppure no.
Questa soluzione funziona perfettamente, ma a ben pensare le cose si possono ulteriormente semplificare, eliminando del tutto la necessità di appesantire lo spazio di memoria con un booleano per ogni nodo. Del resto se ci pensate bene tutti questi valori booleani saranno uguali, tranne quello dell'ultimo nodo.
La soluzione consiste nel riservare un valore del puntatore letterale che indica il nodo successivo come valore speciale, che non punta a nessuna variabile. Il problema tuttavia è scegliere questo valore. In Tcl non vi sono restrizioni sui nomi delle variabili, che possono contenere qualsiasi carattere e iniziare con qualsiasi carattere. Grazie al quoting e al meccanismo di sostituzione delle variabili si possono usare nomi di variabili qualunque, e persino la stringa vuota o un numero possono essere nomi di variabili validi, come mostrano i seguente esempi:
% set {} vuota!
vuota!
% info vars {}
{}
% puts ${}
vuota!
% set 0 zero!
zero!
% info vars 0
0
% puts $0
zero!
Quindi a rigore nessun valore di un puntatore stringa è inutilizzato. All'atto pratico comunque mi pare estremamente raro che un programmatore abbia necessità di utilizzare la stringa nulla come nome di variabile e quindi, visto che dobbiamo scegliere un valore, tanto vale accordarsi sul fatto di non utilizzare la stringa nulla.
Del resto lo stesso accade anche con i puntatori numerici del C. Il valore NULL in realtà corrisponde all'indirizzo di memoria zero: si tratta di un indirizzo di memoria sicuramente indirizzabile come tutti gli altri, ma convenzionalmente decidiamo di non farvi iniziare alcuna variabile, in modo da poter utilizzare l'indirizzo 0 come valore di un puntatore che non punta a nessun elemento.
In questo modo riusciamo a generare una struttura finita senza usare campi discriminanti: l'ultimo nodo della lista è semplicemente quello che ha il puntatore letterale all'elemento successivo pari ad una stringa vuota.
class ListNode {
public variable element
public variable next ""
constructor {args} {
eval configure $args
}
}
Riassumendo ogni nodo della lista contiene due campi stringa: il primo punta all'elemento della lista (il cosiddetto contenuto informativo del nodo) oppure rappresenta proprio questo valore se si tratta di uno scalare (l'applicazione saprà come interpretarlo) e il secondo è invece sempre interpretato dalla nostra classe linkedList come un puntatore letterale: punta al nodo successivo, che è un oggetto della stessa classe di questo nodo (ListNode), oppure segnala la fine della lista se è una stringa vuota.
Il codice completo della classe:
# dataStruct.itcl
package provide dataStruct 0.1
package require Itcl
# interface
namespace eval ::dataStruct {
namespace export linkedList
namespace import ::itcl::*
class linkedList {
# constructor --
#
# Initialize this list as empty. Automatically
# invoked whenever an object is created.
#
# Results:
# Returns this new object name.
constructor {} {}
# destructor --
#
# Destroy this list. Automatically invoked when an object is deleted.
#
destructor {}
# empty --
#
# Empty this list.
method empty {}
# length --
#
# Count the number of elements in this list
#
# Results:
# Returns a decimal string giving the number of elements in this list.
method length {}
# addfront --
#
# Insert an element at the front of this list.
#
# Arguments:
# element element to insert.
# Results:
# Returns an empty string.
method addfront {element}
# addend --
#
# Insert elements at the end of this list.
#
# Arguments:
# element elements to append.
# Results:
# Returns an empty string.
method addend {element}
# getfront --
#
# Return the first element.
#
# Results:
# Returns the first element in this list
# or an empty string if this list is empty.
method getfront {}
# getend -
#
# Return the last element.
#
# Results:
# Returns the last element in this list
# or an empty string if this list is empty.
method getend {}
# removefront --
#
# Removes the first element.
#
# Results:
# Returns the first element removed from this list
# or an empty string if this list is empty.
method removefront {}
# startsearch --
#
# Initializes an element-by-element search through this list.
#
# Results:
# Returns a search identifier.
method startsearch {}
# reset --
#
# Resets a search to start from the first element of this list.
#
# Arguments:
# searchId search identifier returned by the startsearch method.
# Results:
# Returns an empty string.
method reset {searchId}
# getcurrent --
#
# Return the current element of a search.
#
# Arguments:
# searchId search identifier returned by the startsearch method.
# Results:
# Returns the element in the current position, or an empty string
# if all elements of the list have already been visited.
method getcurrent {searchId}
# setcurrent --
#
# Change the current element of a search.
#
# Arguments:
# searchId search identifier returned by the startsearch method.
# element new value of the element.
# Results:
# Returns an empty string.
method setcurrent {searchId element}
# next --
#
# Advance the search on the next element.
#
# Arguments:
# searchId search identifier returned by the startsearch method.
# Results:
# Returns an empty string.
method next {searchId}
# anymore --
#
# Find out if there are more elements.
#
# Arguments:
# searchId search identifier returned by the startsearch method.
# Results:
# Returns 1 if there are any more elements left to be processed in
# an list search, 0 if all elements have already been returned.
method anymore {searchId}
# donesearch --
#
# Terminates a list search, destroying
# all the state associated with that search.
#
# Arguments:
# searchId search identifier returned by the startsearch method.
# Results:
# Returns an empty string.
method donesearch {searchId}
# remove --
#
# Remove the current element of a search.
#
# Arguments:
# searchId search identifier returned by the startsearch method.
# Results:
# Returns an empty string.
method remove {searchId}
# addbefore --
#
# Add an element just before the current element of a search.
#
# Arguments:
# searchId search identifier returned by the startsearch method.
# element element to insert.
# Results:
# Returns an empty string.
method addbefore {searchId element}
# addafter --
#
# Add an element just after the current element of a search.
#
# Arguments:
# searchId search identifier returned by the startsearch method.
# element element to insert.
# Results:
# Returns an empty string.
method addafter {searchId element}
# foreach --
#
# Iterate over all elements in a list.
#
# Arguments:
# varname loop variable that takes on values from the list.
# body Tcl script. See foreach(n).
# Results:
# Returns an empty string.
method foreach {varname body}
protected {
method checksid {searchId}
variable head
variable tail
variable length
}
}
}
# implementation
namespace eval ::dataStruct {
namespace eval linkedList {
namespace import ::itcl::*
class ListNode {
public {
variable element
variable next ""
}
constructor {args} {
eval configure $args
}
}
class Iterator {
public {
variable previous
variable current
}
constructor {head} {
set previous ""
set current $head
}
}
}
# checksid --
#
# Check if a search id references an existant search.
#
# Arguments:
# searchId search identifier to check.
# Returns:
# Returns an empty string if searchId is correct,
# otherwise generates an error.
body linkedList::checksid {searchId} {
if {[find objects $searchId -class Iterator] == ""} {
error "couldn't find search \"$searchId\""
}
return
}
body linkedList::constructor {} {
set head [set tail ""]
set length 0
}
body linkedList::destructor {} {
for {} {$head != ""} {set head $next} {
set next [$head cget -next]
delete object $head
}
}
body linkedList::empty {} {
destructor
constructor
}
body linkedList::length {} {
return $length
}
body linkedList::addfront {element} {
# Add at the front.
set head [ListNode #auto -element $element -next $head]
if {$tail==""} {
set tail $head
}
incr length
return
}
body linkedList::addend {element} {
# Add at the end.
set new [ListNode #auto -element $element]
if {$tail != ""} {
$tail configure -next $new
}
set tail $new
if {$head==""} {
set head $tail
}
incr length
return
}
body linkedList::getfront {} {
if {$head == ""} {
return
}
return [$head cget -element]
}
body linkedList::getend {} {
if {$tail == ""} {
return
}
return [$tail cget -element]
}
body linkedList::removefront {} {
if {$head == ""} {
return
}
set element [$head cget -element]
set next [$head cget -next]
delete object $head
set head $next
if {$head == ""} {
set tail ""
}
incr length -1
return $element
}
body linkedList::startsearch {} {
return [Iterator #auto $head]
}
body linkedList::reset {searchId} {
checksid $searchId
$searchId constructor $head
return
}
body linkedList::getcurrent {searchId} {
checksid $searchId
return [[$searchId cget -current] cget -element]
}
body linkedList::setcurrent {searchId element} {
checksid $searchId
[$searchId cget -current] configure -element $element
return
}
body linkedList::next {searchId} {
checksid $searchId
set current [$searchId cget -current]
if {$current == ""} {
return
}
$searchId configure -previous $current
$searchId configure -current [$current cget -next]
return
}
body linkedList::anymore {searchId} {
checksid $searchId
return [expr {[$searchId cget -current] != ""}]
}
body linkedList::donesearch {searchId} {
checksid $searchId
delete object $searchId
return
}
body linkedList::remove {searchId} {
checksid $searchId
set current [$searchId cget -current]
if {$current == ""} {
return
}
set previous [$searchId cget -previous]
set next [$current cget -next]
if {$current == $head} {
set head $next
} else {
$previous configure -next $next
}
if {$current == $tail} {
set tail $previous
}
delete object $current
$searchId configure -current $next
incr length -1
return
}
body linkedList::addbefore {searchId element} {
checksid $searchId
set current [$searchId cget -current]
if {$current == ""} {
return
}
set new [ListNode #auto -element $element -next $current]
if {$current == $head} {
set head $new
} else {
[$searchId cget -previous] configure -next $new
}
$searchId configure -previous $new
incr length
return
}
body linkedList::addafter {searchId element} {
checksid $searchId
set current [$searchId cget -current]
if {$current == ""} {
return
}
set next [$current cget -next]
set new [ListNode #auto -element $element -next $next]
if {$current == $tail} {
set tail $new
}
$current configure -next $new
incr length
return
}
body linkedList::foreach {varname body} {
for {set p $head} {$p != ""} {set p [$p cget -next]} {
upvar 1 $varname loopvar
set loopvar [$p cget -element]
uplevel 1 $body
}
return
}
}
La variabili membro head, tail, length sono state dichiarate come protette anzichè come private, come pure il metodo checksid, ma per ora potete ignorare questa differenza, che sarà chiarita quando parleremo dell'ereditarietà.
Quando viene creato un oggetto di questa classe, inizialmente rappresenta la lista vuota:
linkedList pets
Proviamo ora ad aggiungere qualche elemento in sequenza:
pets addend "cat" pets addend "dog" pets addend crocodile pets addend "canary"
Vediamo poi quali oggetti sono stati creati:
% itcl::find objects ::* ::pets ::dataStruct::linkedList::listNode0 ::dataStruct::linkedList::listNode1 ::dataStruct::linkedList::listNode2 ::dataStruct::linkedList::listNode3
Infine percorriamo la lista per stamparne ciascun elemento nell'ordine in cui sono collegati:
% pets foreach pet {
puts $pet
}
cat
dog
crocodile
canary
Per avere un'incapsulazione perfetta, i campi di ListNode non dovrebbero essere dichiarati pubblici. Dovrebbe essere possibile accedervi solo dalla classe linkedList. Come è stato fatto, la classe linkedList non dovrà mai ritornare ai suoi clienti riferimenti ad oggetti linkedList. Non solo per riaggiustare i puntatori, ma anche per cambiare un elemento della lista, il codice cliente dovrà fare riferimento alla classe linkedList, piuttosto che accedere direttamente agli oggetti ListNode.
I motivi per cui conviene una forte incapsulazione sono vari: in questo modo si semplifica l'uso delle liste, si prevengono possibili errori da parte dell'utilizzatore e, se necessario, si rende possibile modificare la rappresentazione (ad es. in una lista doppiamente linkata) senza essere costretti a modificare il codice del cliente.
Per rafforzare l'incapsulazione ho riunito la classe linkedList, insieme ad altre classi che implementano nuove strutture dati, in uno spazio nomi che ho chiamato dataStruct.
Questo namespace esporta solo comando linkedList. Invece di porre ListNode nel namespace ::dataStruct come linkedList, ho preferito porlo nel namespace innestato ::dataStruct::linkedList, lo stesso in cui si trovano gli ListNode creati dai metodi della classe linkedList. Tramite il comando namespace import si può importare linkedList ma non ListNode, in quanto questo non è esportato dal namespace ::dataStruct::linkedList:
% namespace import ::dataStruct::* % namespace import ::dataStruct::linkedList::* % info commands ListNode % info commands linkedList linkedList
Se proprio si vuole, si può ancora utilizzare il comando ListNode utilizzando il suo nome pienamente qualificato ::dataStruct::linkedList::ListNode; allo stesso modo si può accedere dall'esterno ai nodi di una lista (es. ::dataStruct::linkedList::listNode0). Purtroppo questo è ancora possibile perchè Tcl non offre meccanismi di controllo di accesso sui namespace, tuttavia adesso è più chiaro che ListNode non fa parte dell'interfaccia della nostra libreria ed è piuttosto una classe privata del namespace ::dataStruct::linkedList.
Notate la presenza del distruttore per liberare la memoria allocata per i nodi quando viene distrutta l'intera lista. Se gli elementi sono puntatori ad altri oggetti, lo spazio va liberato dal programma chiamante, prima che ne perda tutti i riferimenti ([incr Tcl] non ha un garbage collector).
La variabile membro protetta length tiene traccia della lunghezza corrente della lista e il metodo accessore pubblico length ne ritorna il valore con costo computazionale costante.
La variabile membro privata tail invece punta all'ultimo elemento della lista. L'inserimento di elementi in testa tramite addfront o in coda tramite addend ha un costo computazionale costante, mentre in posizione intermedia il costo è limitato da un multiplo della lunghezza della lista, in quanto occorre scandire la lista fino a trovare il punto di inserimento.
La definizione di ListNode è stata messa nell'implementazione, in modo da tenere l'interfaccia più pulita. Inoltre ogni metodo dell'interfaccia è stato documentato.
Il namespace dataStruct è stato inserito in un package con lo stesso nome, in modo da facilitarne il caricamento e il controllo delle versioni.
Per utilizzare il package dataStruct, occorre aggiungere la directory che lo contiene all'auto-path, ad es. se si trova nella directory corrente:
lappend auto_path .
Poi si usa il comando package(n) per caricarlo:
package require dataStruct
A questo punto si possono invocare i nuovi comandi o qualificandoli pienamente:
::dataStruct::linkedList petsoppure importandoli nel namespace corrente:
namespace import ::dataStruct::* linkedList pets
La classe linkedList è basata sui "pattern iterator". Un iteratore rappresenta un modo per accedere sequenzialmente agli elementi di un oggetto aggregato (di cui la lista è un semplice esemplare), senza esporre i dettagli della rappresentazione interna ed utilizzando una interfaccia standard (ovvero che può essere la stessa per diversi tipi di oggetti aggregati).
Il metodo foreach che abbiamo implementato anche per le linkedList, così come pure il comando foreach(n) sulle liste di stringhe, è già un esempio di iteratore, in quanto il suo uso astrae dalla rappresentazione interna della lista. È uno degli iteratori più semplici.
Un altro iteratore più flessibile è quello fornito da Tcl sugli array. Rivedete i sottocomandi startsearch, nextelement, anymore e donesearch di array(n) nel paragrafo manipolazione degli array. Tramite questi comandi è possibile avere in corso più ricerche indipendenti in uno stesso array e una ricerca non deve essere completata nell'arco di un unico comando come con foreach: ogni ricerca è identificata tramite un id di ricerca. L'id identifica una struttura dati che contiene lo stato della ricerca, ma che è nascosta agli utenti. Si usano i sottocomandi ricordati prima per ottenere il prossimo elemento dell'aggregato, terminare la scansione o interrogare se ci sono altri elementi non ancora analizzati. Questo è un iteratore di tipo esterno e permette un maggiore controllo del processo di iterazione.
Notate però che con i sottocomandi di ricerca di array, se vengono aggiunti o eliminati elementi dall'array quando ancora alcune iterazioni sono aperte, tutte le le ricerche correnti vengono automaticamente terminate, come se fosse stato invocato array donesearch su ciascuna ricerca.
Il nostro iteratore è ancora più potente e permette anche la modifica delle liste. Sull'array questo non era necessario, essendoci già l'indicizzazione. I metodi dell'iteratore sono startsearch, reset, getcurrent, setcurrent, next, anymore e donesearch.
Se dovessimo accedere direttamente ai nodi di una lista, tipicamente scandiremmo la lista tramite cicli di questo tipo:
for {set previous ""; set current $head} {$current != ""} {set previous $current; set current [$current cget -next]} {
set elem [$current cget -element]
# do something with $elem ...
}
Notate che stiamo mantenendo traccia anche del puntatore all'elemento precedente. Questo semplifica le operazioni di inserimento prima di un nodo o di rimozione dell'ultimo nodo.
Se non usiamo il previous, l'inserimento prima del nodo corrente sarebbe ancora possibile, con un piccolo trucco: creiamo un nuovo nodo che è un clone del nodo corrente (si copia sia l'elemento che il valore del puntatore next). Si inserisce questo nodo copia dopo il nodo corrente esattamente come nel primo caso e infine si cambia il contenuto informativo del nodo corrente con il valore da inserire. Alla fine si pone come corrente il nodo nuovo nodo clone.
Per quanto riguarda invece la rimozione di un nodo corrente intermedio, il trucco consiste nel copiare il contenuto informativo del nodo successivo nel nodo corrente e poi si rimuove il nodo successivo (operazione banale, conoscendo il suo precedente, che è appunto il nodo corrente). Purtroppo però questo trucco non è applicabile se il nodo corrente da rimuovere è l'ultimo.
A questo punto siamo di fronte ad una scelta: o manteniamo anche il puntatore al penultimo nodo (aggiungendo una variabile membro tailprevious insieme a head e tail), oppure decidiamo di mantenere il campo previous durante le scansioni. Entrambe le soluzioni hanno vantaggi e svantaggi.
Nella classe linkedList ho implementato la seconda soluzione, senza utilizzare i trucchi spiegati prima: lo stato corrente di un'iterazione viene mantenuto in un oggetto di classe Iterator e comprende, non solo un puntatore al nodo corrente, ma anche uno al nodo precedente (quest'ultimo vale "" se il nodo corrente è il nodo testa).
Così il metodo startsearch corrisponde alla sezione di inizializzazione del for visto prima, anymore corrisponde al test condizionale e next alla sezione di incremento (terzo parametro del for). Il metodo getcurrent ritorna il valore dell'elemento corrente e il metodo setcurrent permette di cambiarlo. reset è opzionale e l'ho aggiunto solo per comodità: se non lo avessi, potrei ottenere lo stesso effetto di resettare un iteratore distruggendo l'oggetto e ricreandone uno nuovo (ovvero utilizzando gli iteratori come oggetti usa-e-getta).
Gli iteratori sono oggetti privati del namespace ::dataStruct::linkedList. I clienti della classe linkedList non creano direttamente questi oggetti anzi non sanno nemmeno che esistono, ma delegano la creazione al metodo startsearch, che semplicemente ne ritorna il nome non qualificato (analogo del searchId dell'iteratore di un array).
Ecco un esempio d'uso che illustra alcune manipolazione effettuate sulla lista senza la manipolazione diretta dei puntatori:
lappend auto_path .
package require dataStruct
namespace import ::dataStruct::*
linkedList pets
pets addend cat
pets addend dog
pets addend crocodile
pets addend canary
for {set sid [pets startsearch]} {[pets anymore $sid]} {pets next $sid} {
if {[pets getcurrent $sid] == "dog"} {
pets setcurrent $sid doggy
}
if {[pets getcurrent $sid] == "crocodile"} {
pets remove $sid ;# after this the current element becomes canary
break
}
}
pets reset $sid
pets addbefore $sid hamster
pets addafter $sid horse
pets donesearch $sid
pets foreach pet {
puts $pet
}
L'output di questo programma di test è:
hamster cat horse doggy canary
Nonostante si sia evitato di manipolare direttamente i puntatori, i rischi di errore si sono solo ridotti e non annullati del tutto. Un errore comune che si può commettere quando si utilizzano dei puntatori è di tentare di deferenziare un riferimento che non esiste. Nel semplice esempio che segue su una lista vengono accesi due iteratori: il primo viene utilizzato per rimuovere l'elemento di testa. Poi si tenta di accedere all'elemento di testa appena rimosso tramite l'altro iteratore e questo produce un errore:
linkedList test test addfront one test addfront two set i1 [test startsearch] set i2 [test startsearch] test remove $i1 test getcurrent $i2
invalid command name "listNode1"
while executing
"[$searchId cget -current] cget -element"
(object "::test" method "::dataStruct::linkedList::getcurrent" body line 4)
invoked from within
"test getcurrent $i2
"
Questo genere di errori potrebbe essere evitato se la memoria dinamica fosse gestita tramite la tecnica di deallocazione automatica o garbage collection. Un garbage collector tiene traccia dei riferimenti esistenti ad un oggetto e libera la memoria ad esso associata solo quando non vi sono più riferimenti (l'ultimo riferimento esistente è stato perso). In questo modo l'operazione di remove non rimuoverebbe subito il primo nodo dalla memoria, in quanto vi è ancora un'iteratore (i2) che lo riferisce come nodo corrente. Un garbage collector offre comodità e maggiore protezione dagli errori nella gestione della memoria dinamica, ma per operare richiede un costo computazionale ulteriore, in quanto occorre tenere sotto traccia tutti i riferimenti. [incr Tcl] non è attualmente dotata di garbage collector, quindi rimane compito del programmatore fare attenzione.
Nell'intento di mostrare meglio le relazioni tra le tre classi che abbiamo scritto, ho disegnato un class diagram o diagramma delle classi. Questo mi offre anche l'occasione di introdurre un po' del linguaggio UML, una notazione grafica utile per l'analisi dei sistemi software ad oggetti:
Class diagram generato dal sorgente
tramite TCM
In questo disegno ciascuna classe è rappresentata con un box suddiviso in tre compartimenti: dall'alto verso il basso, il primo contiene il nome della classe; il secondo le proprietà locali (attributi) e il terzo le operazioni (metodi) che definiscono il comportamento delle istanze (oggetti) della classe.
Il simboli + e # davanti ai nomi degli attributi e delle operazioni indicano il livello di protezione e stanno rispettivamente per public e protected (si usa invece - per private, mentre ~ indica la visibilità di package). Gli argomenti dei metodi si indicano dopo il nome tra parentesi tonde con una sintassi del tipo nomeparam:tipoparam, alla Pascal. Il nome di un parametro si può omettere qualora il suo significato sia già evidente dal tipo scrivendo solo :tipoparam.
Piuttosto che indicare ripetutamente come tipo string, che è l'unico tipo nativo in Tcl, ho inventato dei nomi di tipi per chiarire meglio l'interpretazione che viene data alle stringhe (integer significa intero, any indica un tipo generico, varname un nome di variabile, script uno script Tcl e Iterator è il tipo corrispondente alla classe Iterator).
Il simbolo / indica semplicemente che l'attributo length è derivato, ovvero che, anche se non direttamente rappresentato, potrebbe essere calcolato ogni volta che ne viene richiesto il valore. Infatti l'associazione front ci fornisce la testa della lista e possiamo quinda percorrerla interamente, semplicemente per contarne gli elementi ogni qualvolta ci serve la lunghezza della lista. Questo naturalmente non significa che conviene sempre fare così: infatti in generale è più efficiente tenere traccia della lunghezza.
Una linea disegnata tra due classi rappresenta una associazione di tipo binaria. Dal punto di vista formale (matematico) il termine associazione è un sinonimo del termine relazione della teoria degli insiemi. Questa definisce una relazione come un sottoinsieme del prodotto cartesiano di due o più insiemi (se gli insiemi sono solo due la relazione è un insieme di coppie ordinate formate da alcuni elementi scelti dai due insiemi e viene detta binaria). Quindi nel nostro caso le classi rappresentano l'insieme dei loro oggetti e una associazione binaria tra una classe A e B non è altro che un insieme di coppie del tipo (a, b), dove a è un oggetto della classe A e b è un oggetto della classe B. Le annotazioni agli estremi delle linee indicano le proprietà (o vincoli) di molteplicità delle associazioni se sono del tipo numero [.. numero], mentre se sono alfanumeriche indicano il ruolo che la classe alla fine della linea gioca nell'associazione.
Con l'aggiunta dei ruoli, formalmente le istanze di una associazione sono ora delle coppie etichettate. Ad esempio se il ruolo di A è ruoloA, mentre il ruolo di B è ruoloB, le coppie sono del tipo (ruoloA:a, ruoloB:b).
Il significato delle moltiplicità è invece di imporre un ulteriore vincolo sulle associazioni riguardo il numero minimo e massimo di istanze che vi partecipano per ciascuna delle classi coinvolte. Ad esempio, considerando l'associazione previous, le molteplicità impongono che ogni istanza di Iterator sia legata a non più di una istanza di ListNode (il nodo precedente è NULL oppure è uno solo); viceversa data una istanza di ListNode, questa può essere il nodo precedente di nessuno o di un numero qualsiasi di iteratori. 0..* non pone alcun vincolo minimo o massimo ed è il default in mancanza di specifica diversa (quindi si potrebbe anche evitare di indicare).
Tornando al nostro diagramma, ogni istanza (oggetto) di linkedList è legato ad una ed una sola istanza di ListNode oppure nessuna (nel solo caso di lista vuota) tramite l'associazione "front". Quest'ultima istanza gioca il ruolo di testa (head) della lista. Similmente ogni istanza di ListNode può essere la testa di al più di una lista, oppure di nessuna (se si tratta di un nodo intermedio o del nodo coda in una lista con più di due elementi). Poichè il ruolo di linkedList nell'associazione front non è indicato, esso è per default coincidente con il nome della classe, ovvero linkedList. Questo è plausibile in quanto in questa associazione linkedList gioca proprio il ruolo di una lista!
Le freccie piene nere indicano la navigabilità o responsabilità sulle associazioni. Ad esempio una linkedList ha la responsabilità di sapere quale ListNode è la sua testa; viceversa non è richiesto che un ListNode sappia di quale lista è la testa o meno. Se la navigabilità di una associazione non viene indicata, significa che è o sconosciuta, o non ancora determinata oppure che l'associazione deve essere navigabile in entrambe le direzioni (associazione bidirezionale).
Notate che l'associazione binaria link insiste due volte sulla stessa classe ListNode e che inoltre si tratta di una associazione non simmetrica. Infatti ad esempio il fatto che esista un link dal nodo a al nodo b, non implica che esiste un link dal nodo b al nodo a, anzi questo certamente non esiste, trattandosi di una lista linkata in una sola direzione. Per questo tipo di associazioni è indispensabile indicare i ruoli (nel nostro caso previous e next) pena ambiguità nell'interpretazione delle istanze dell'associazione. Ad esempio se dico che il nodo a è linkato al nodo b e non specifico i ruoli, non c'è modo di capire se è a che è linkato verso b o viceversa. Notate inoltre che poichè il nodo testa non ha precedente e il nodo coda non ha successivo, le molteplicità minime dell'associazione link devono essere 0 e non 1, in modo che la partecipazione di un nodo alla associazione (sia nel ruolo di next sia nel ruolo di previous) sia opzionale e non obbligatoria.
Notate infine che la classe linkedList è dipendente anche dalla classe Iterator, in quanto ha alcuni metodi (es. startsearch) che hanno un parametro di tipo Iterator. Volendo anche questa dipendenza potrebbe essere rappresentata in UML utilizzando una freccia tratteggiata con punta aperta che collega linkedList a Iterator.
Notate come le associazioni, nell'implementazione, sono diventate attributi delle classi che ne hanno responsabilità.
In modo simile a come fatto per le liste concatenate, si potrebbero implementare in [incr Tcl] anche strutture dinamiche più complesse, come alberi o grafi, senza ricorrere al C e con una perdita di efficienza in molti casi in pratica trascurabile. Il lettore interessato è invitato a provare autonomamente, facendo riferimento a qualche buon testo sugli algoritmi e le strutture di dati come quelli del Prof. Niklaus Wirth per i dettagli teorici necessari.
« Esempio: la classe pack • Appunti di Tcl/Tk • Esempio: un derivatore simbolico »